VMware introduced a new storage feature in vSphere 6.0 which was designed as a flexible option to better handle certain storage problems. Cormac Hogan did a fine job introducing the feature here. Starting with vSphere 6.0 and continuing on in vSphere 6.5, each block storage device (VMFS or RDM) is configured with an option called action_OnRetryErrors. Note that in vSphere 6.0 and 6.5, the default value is off meaning the new feature is effectively disabled and there is no new storage error handling behavior observed.
This value can be seen with the esxcli storage nmp device list command.
vSphere 6.0/6.5:
esxcli storage nmp device list | grep -A9 naa.6000d3100002b90000000000000ec1e1
naa.6000d3100002b90000000000000ec1e1
Device Display Name: sqldemo1vmfs
Storage Array Type: VMW_SATP_ALUA
Storage Array Type Device Config: {implicit_support=on; explicit_support=off; explicit_allow=on; alua_followover=on; action_OnRetryErrors=off; {TPG_id=61459,TPG_state=AO}{TPG_id=61460,TPG_state=AO}{TPG_id=61462,TPG_state=AO}{TPG_id=61461,TPG_state=AO}}
Path Selection Policy: VMW_PSP_RR
Path Selection Policy Device Config: {policy=rr,iops=1000,bytes=10485760,useANO=0; lastPathIndex=0: NumIOsPending=0,numBytesPending=0}
Path Selection Policy Device Custom Config:
Working Paths: vmhba1:C0:T2:L141, vmhba1:C0:T3:L141, vmhba2:C0:T3:L141, vmhba2:C0:T2:L141
Is USB: false
If vSphere loses access to a device on a given path, the host will send a Test Unit Ready (TUR) command down the given path to check path state. When action_OnRetryErrors=off, vSphere will continue to retry for an amount of time because it expects the path to recover. It is important to note here that a path is not immediately marked dead when the first Test Unit Ready command is unsuccessful and results in a retry. It would seem many retries in fact and you’ll be able to see them in /var/log/vmkernel.log. Also note that a device typically has multiple paths and the process will be repeated for each additional path tried assuming the first path is eventually marked as dead.
Starting with vSphere 6.7, action_OnRetryErrors is enabled by default.
vSphere 6.7:
esxcli storage nmp device list | grep -A9 naa.6000d3100002b90000000000000ec1e1
naa.6000d3100002b90000000000000ec1e1
Device Display Name: sqldemo1vmfs
Storage Array Type: VMW_SATP_ALUA
Storage Array Type Device Config: {implicit_support=on; explicit_support=off; explicit_allow=on; alua_followover=on; action_OnRetryErrors=on; {TPG_id=61459,TPG_state=AO}{TPG_id=61460,TPG_state=AO}{TPG_id=61462,TPG_state=AO}{TPG_id=61461,TPG_state=AO}}
Path Selection Policy: VMW_PSP_RR
Path Selection Policy Device Config: {policy=rr,iops=1000,bytes=10485760,useANO=0; lastPathIndex=2: NumIOsPending=0,numBytesPending=0}
Path Selection Policy Device Custom Config:
Working Paths: vmhba1:C0:T2:L141, vmhba1:C0:T3:L141, vmhba2:C0:T3:L141, vmhba2:C0:T2:L141
Is USB: false
If vSphere loses access to a device on a given path, the host will send a Test Unit Ready (TUR) command down the given path to check path state. When action_OnRetryErrors=on, vSphere will immediately mark the path dead when the first retry is returned. vSphere will not continue the retry TUR commands on a dead path.
This is the part where VMware thinks it’s doing the right thing by immediately fast failing a misbehaving/dodgy/flaky path. The assumption here is that other good paths to the device are available and instead of delaying an application while waiting for path failover during the intensive TUR retry process, let’s fail this one bad path right away so that the application doesn’t have to spin its wheels.
However, if all other paths to the device are impacted by the same underlying (and let’s call it transient) condition, what happens is that each additional path iteratively goes through the process of TUR, no retry, immediately mark path as dead, move on to the next path. When all available paths have been exhausted, All Paths Down (APD) for the device kicks in. If and when paths to an APD device become available again, they will be picked back up upon the next storage fabric rescan, whether that’s done manually by an administrator, or automatically by default every 300 seconds for each vSphere host (Disk.PathEvalTime). From an application/end user standpoint, I/O delay for up to 5 minutes can be a painfully long time to wait. The irony here is that VMware can potentially turn a transient condition lasting only a few seconds into a more of a Permanent Device Loss like condition.
All of the above leads me to a support escalation I got involved in with a customer having an Active/Passive block storage array. Active/Passive is a type of array which has multiple storage processors/controllers (usually two) and LUNs are distributed across the controllers in an ownership model whereby each controller owns both the LUNs and the available paths to those LUNs. When an active controller fails or is taken offline proactively (think storage processor reboot due to a firmware upgrade), the paths to the active controller go dark, the passive controller takes ownership of the LUNs and lights up the paths to them – a process which can be measured in seconds, typically more than 2 or 3, often much more than that (this dovetails into the discussion of virtual machine disk timeout best practices). With action_OnRetryErrors=off, vSphere tolerates the transient path outage during the controller failover. With action_OnRetryErrors=on, it doesn’t – each path that goes dark is immediately failed and we have APD for all the volumes on that controller in a fraction of a second.
The problem which was occurring in this customer escalation was a convergence of circumstances:
- The customer was using vSphere 6.7 and its defaults
action_OnRetryErrors=on - The customer was using an Active/Passive storage array
- The customer virtualized Microsoft Windows SQL cluster servers (cluster disk resources are extremely sensitive to APDs in the hypervisor and immediately fail when it detects a dependent cluster disk has been removed – a symptom introduced by APD)
- The customer was testing controller failovers
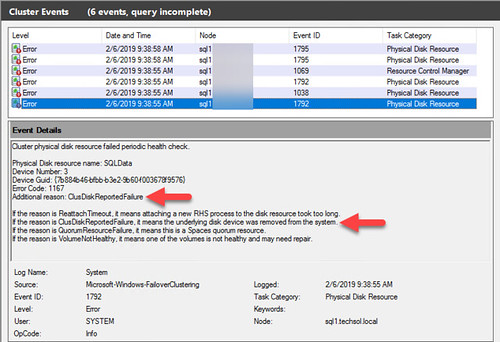
To resolve the problem in vSphere 6.7, action_OnRetryErrors needs to be disabled for each device backed by the Active/Passive storage array. This must be performed on every host in the cluster having access to the given devices (again, these can be VMFS volumes and/or RDMs). There are a few ways to go about this.
To modify the configuration without a host reboot, take a look at the following example. A command such as this would need to be run on every host in the cluster, and for each device (ie. in an 8 host cluster with 8 VMFS/RDMs, we need to identify the applicable naa.xxx IDs and run 64 commands. Yes, this could be scripted. Be my guest.):
esxcli storage nmp satp generic deviceconfig set -c disable_action_OnRetryErrors -d naa.6000d3100002b90000000000000ec1e1
I don’t prefer that method a whole lot. It’s tedious and error prone. It could result in cluster inconsistencies. But on the plus side, a host reboot isn’t required, and this setting will persist across reboots. That also means a configuration set at this device level will override any claim rules that could also apply to this device. Keep this in mind if a claim rule is configured but you’re not seeing the desired configuration on any specific device.
The above could also be scripted for a number of devices on a host. Here’s one example. Be very careful that the base naa.xxx string matches all of the devices from one array that should be configured, and does not modify devices from other array types that should not be configured. Also note that this script is a one liner but for blog formatting purposes I manually added a line break starting with esxcli.:
for i in `ls /vmfs/devices/disks | grep -v ":" | grep -i naa.6000D31`; do echo $i;
esxcli storage nmp satp generic deviceconfig set -c disable_action_OnRetryErrors -d $i; doneNow to verify:
for i in `ls /vmfs/devices/disks | grep -v ":" | grep -i naa.6000D31`; do echo $i;
esxcli storage nmp device list | grep -A2 $i | egrep -io action_OnRetryErrors=\\w+; doneI like adding a SATP claim rule using a vendor device string a lot better, although changes to claim rules for existing devices generally requires a reboot of the host to reclaim existing devices with the new configuration. Here’s an example:
esxcli storage nmp satp rule add -s VMW_SATP_ALUA -V COMPELNT -P VMW_PSP_RR -o disable_action_OnRetryErrors
Here’s another example using quotes which is also acceptable and necessary when setting multiple option string parameters (refer to this):
esxcli storage nmp satp rule add -s “VMW_SATP_ALUA” -V “COMPELNT” -P “VMW_PSP_RR” -o “disable_action_OnRetryErrors”
When a new claim rule is added, claim rules can be reloaded with the following command.
esxcli storage core claimrule load
Keep in mind the new claim rule will only apply to unclaimed devices. Newly presented devices will inherit the new claim rule. Existing devices which are already claimed will not until the next vSphere host reboot. Devices can be unclaimed without a host reboot but all I/O to the device must be halted – somewhat of a conundrum if we’re dealing with production volumes, datastores being used for heartbeating, etc. Assuming we’re dealing with multiple devices, a reboot is just going to be easier and cleaner.
I like claim rules here better because of the global nature. It’s one command line per host in the cluster and it’ll take care of all devices from the Active/Passive storage array vendor. No need to worry about coming up with and testing a script. No need to worry about spending hours identifying the naa.xxx IDs and making all of the changes across hosts. No need to worry about tagging other storage vendor devices with an improper configuration. Lastly, the claim rule in effect is visible in a SATP claim rule list (sincere apologies for the formatting – it’s bad I know):
esxcli storage nmp satp rule list
Name Device Vendor Model Driver Transport Options Rule Group Claim Options Default PSP PSP Options Description
——————- —— ——– —————- —— ——— —————————- ———- ———————————– ———– ———– ———————————————–
VMW_SATP_ALUA COMPELNT disable_action_OnRetryErrors user VMW_PSP_RR
By the way… to remove the SATP claim rules above respectively:
esxcli storage nmp satp rule remove -s VMW_SATP_ALUA -V COMPELNT -P VMW_PSP_RR -o disable_action_OnRetryErrors
esxcli storage nmp satp rule remove -s “VMW_SATP_ALUA” -V “COMPELNT” -P “VMW_PSP_RR” -o “disable_action_OnRetryErrors”
The bottom line here is there may be a number of VMware customers with Active/Passive storage arrays, running vSphere 6.7. If and when planned or unplanned controller/storage processor failover occurs, APDs may unexpectedly occur, impacting virtual machines and their applications, whereas this was not the case with previous versions of vSphere.
In closing, I want to thank VMware Staff Technical Support Engineering for their work on this case and ultimately exposing “what changed in vSphere 6.7” because we had spent some time trying to reproduce this problem on vSphere 6.5 where we had an environment similar to what the customer had and we just weren’t seeing any problems.
References:
No Failover for Storage Path When TUR Command Is Unsuccessful
Storage path does not fail over when TUR command repeatedly returns retry requests (2106770)
Handling Transient APD Conditions
VSPHERE 6.0 STORAGE FEATURES PART 6: ACTION_ONRETRYERRORS
Updated 2-20-19: VMware published a KB article on this issue today:
ESXi 6.7 hosts with active/passive or ALUA based storage devices may see premature APD events during storage controller fail-over scenarios (67006)
















Thanks for posting this. We are in the middle of planning our upgrade to 6.7 U1. I will add this to our configuration list.
Is this active/passive setup the only time one needs to worry about this setting??
What about other kinds of host/storage setups??
For example: 2-3 hosts with SAN or NAS storage?? with no active/passive involved??