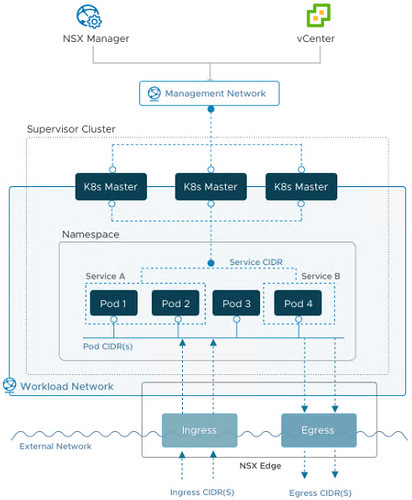
Last month, the general availability of Amazon Elastic Kubernetes Service Anywhere was announced. Much like vSphere with Tanzu (TKGs) and Tanzu Kubernetes Grid (TKGm), EKS Anywhere (open source) is a deployment option for Amazon EKS that enables the deployment of Kubernetes clusters on premises using VMware vSphere 7.
I had an opportunity this past week to install EKS Anywhere in two different lab environments. Having worked with vSphere with Tanzu quite a bit last year, I was excited to see how the two compared. The EKS Anywhere documentation covers the requirements, configuration of the administrative machine, as well as the creation of a local or production cluster. I found the documentation to fairly straight forward. In a perfect world with all steps working correctly, deployment start to finish could take 30 minutes or less. However, I did run into some challenges. With EKS Anywhere basically being brand new (current version 0.5.0), I found there is little to no troubleshooting information available in the community so I did the best I could and took many notes along the way until I achieved a successful and repeatable deployments. In this blog post, I’ll step through the deployment process, I’ll highlight the challenges I encountered, and the corresponding resolutions or workarounds.
Reminder: I’m stepping through the EKS Anywhere documentation. For the following sections, it may be helpful to have this document open for reference. In addition, I’m not covering every step. The intent is to bridge some gaps where things didn’t go so smoothly.
Install EKS Anywhere
The documentation has us start by getting what they call the administrative machine set up. I’m using Ubuntu Server (Option 2 – Manual server installation ubuntu-20.04.3-live-server-amd64.iso). Nothing to do with EKS Anywhere but rather three basic Linux tips here:
- When installing Ubuntu Server, enable openssh when prompted for remote ssh access later
- After installing Ubuntu Server, install net-tools: sudo apt install net-tools
- open-vm-tools will be installed by default. No need to install VMware Tools
Looking at the EKS Anywhere Create Cluster diagram and reading slightly ahead, we know this administrative machine will host the bootstrap cluster which is used to build out the EKS Anywhere control plane and worker nodes on vSphere. So after installing Ubuntu Server, we’re going to need to install some additional tools.
Install Homebrew prerequisites:
sudo apt update
sudo apt-get install build-essential procps curl file git
Install Homebrew:
sudo apt update
/bin/bash -c “$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)”
When Homebrew installation is complete, be sure to follow the two next steps to add Homebrew to the path so future shell commands are successful. Basically copy and paste the two commands that are provided. For my installation under the administrator created account, this was:
echo ‘eval “$(/home/linuxbrew/.linuxbrew/bin/brew shellenv)”‘ >> /home/administrator/.profile
eval “$(/home/linuxbrew/.linuxbrew/bin/brew shellenv)”
Set up repository and install Docker Engine (I used the Docker repository method):
sudo apt-get update
sudo apt-get install apt-transport-https ca-certificates curl gnupg lsb-release
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg –dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
echo “deb [arch=$(dpkg –print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable” | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io
When testing Docker Engine commands (docker run hello-world as an example), you may run into an error similar to:
docker: Got permission denied while trying to connect to the Docker daemon socket at unix [redacted]
Fix using the following commands (source, this is also covered in the Troubleshooting section of the EKS Anywhere documentation):
sudo groupadd docker (may produce an error that docker group already exists – ok)
sudo usermod -aG docker $USER
newgrp docker (might be unnecessary – I performed anyway)
Next up, we install eksctl and eksctl-anywhere using Homebrew. According to the documentation: This package will also install kubectl and the aws-iam-authenticator which will be helpful to test EKS clusters. I found this to be false, for kubectl anyway. Go ahead and follow the instructions:
brew install aws/tap/eks-anywhere
In my experience, kubectl was nowhere to be found when issuing kubectl commands in the shell. To remedy this, I used Homebrew to install kubectl:
brew install kubernetes-cli
Update 11/9/21: AWS Development has confirmed kubectl is not being installed as part of the eks-anywhere Homebrew installer. This is a bug and they are working on a Github update here and here.
This wraps up the challenges for the administrative machine. Not too bad and there was plenty of community help to get me through this part. I think with a little documentation clean up, there’d be no surprises here.
Create production cluster
With the administrative machine ready to go, it’s time to get to the fun stuff – deploying EKS Anywhere. I didn’t bother following the instruction to create local cluster because I wanted EKS Anywhere deployed to vSphere infrastructure. That means skipping ahead to the section Create production cluster.
The Prerequisite Checklist has us create a few objects which might not already exist using the vSphere Client. Namely an arbitrarily named Resource Pool and VM folder. Of course a vCenter Server, a Datacenter, a Datastore, and a Network (portgroup) must also exist. Note: Datastore Clusters and Datastores that are a member of a Datastore Cluster will not work with EKS Anywhere deployment – use a standard block, file, or vVol Datastore (or vSAN). There’s one undocumented resource that I did not see mentioned in the documentation which I’ll cover shortly.
After generating the cluster config yaml file and applying it, the administrative machine autonomously goes through a large number of steps to set up the control plane and worker nodes on vSphere. It is this series of steps where I ran into a number of EKS Anywhere related challenges that I had to work through. I’ll go through each of them in roughly the order that I remember they presented themselves. By the way, any time the autonomous script fails, the process is to clean up what it did and start over by re-running it. Lastly, what I’m going to continue calling “the script”, merely means applying the cluster deployment eksa-cluster.yaml.
After validating the vSphere environment, one of the first steps that is performed is the download and templating of the Bottlerocket container image. The image is initially stored as a vSphere content library item so a content library named eks-a-templates is first created. Then the download and import into the content library occurs. For whatever reason, the download process fails, a lot, with the following error:
Validation failed {“validation”: “vsphere Provider setup is valid”, “error”: “failed importing template into library: error importing template: govc: The import of library item 3df0dd7f-2d88-458b-835d-ab83fa6a9107 has failed. Reason: Error transferring file bottlerocket-v1.21.2-eks-d-1-21-4-eks-a-1-amd64.ova to ds:///vmfs/volumes/vvol:afedfe12b3e24fb4-8a0daa5002ac9644//contentlib-d7538b36-1c53-4cba-9f7c-84e78824e456/3df0dd7f-2d88-458b-835d-ab83fa6a9107/bottlerocket-v1.21.2-eks-d-1-21-4-eks-a-1-amd64_fb1094fd-0a42-4ff2-928c-3c0a9cdd30fd.ova?serverId=c2fdf804-b0a0-4bcb-99be-9dab04afa64f. Reason: Error during transfer of ds:///vmfs/volumes/vvol:afedfe12b3e24fb4-8a0daa5002ac9644//contentlib-d7538b36-1c53-4cba-9f7c-84e78824e456/3df0dd7f-2d88-458b-835d-ab83fa6a9107/bottlerocket-v1.21.2-eks-d-1-21-4-eks-a-1-amd64_fb1094fd-0a42-4ff2-928c-3c0a9cdd30fd.ova?serverId=c2fdf804-b0a0-4bcb-99be-9dab04afa64f: IO error during transfer of ds:/vmfs/volumes/vvol:afedfe12b3e24fb4-8a0daa5002ac9644/contentlib-d7538b36-1c53-4cba-9f7c-84e78824e456/3df0dd7f-2d88-458b-835d-ab83fa6a9107/bottlerocket-vmware-k8s-1.21-x86_64-1.2.0-ccf1b754_fb1094fd-0a42-4ff2-928c-3c0a9cdd30fd.vmdk: Pipe closed.\n”, “remediation”: “”}
Error: failed to create cluster: validations failed
If the script is run again with no cleanup, the following error will occur:
Validation failed {“validation”: “vsphere Provider setup is valid”, “error”: “failed deploying template: error deploying template: govc: 400 Bad Request: {\”type\”:\”com.vmware.vapi.std.errors.invalid_argument\”,\”value\”:{\”error_type\”:\”INVALID_ARGUMENT\”,\”messages\”:[{\”args\”:[],\”default_message\”:\”Specified library item is not an OVF.\”,\”id\”:\”com.vmware.ovfs.ovfs-main.ovfs.invalid_library_item\”}]}}\n”, “remediation”: “”}
Error: failed to create cluster: validations failed
It was at this point that I learned that the eks-a-templates content library needs to be deleted before re-running the script. Continue repeating this process until you get a good Bottlerocket download. Eventually it will complete 100% without failing. Once you get a good download of Bottlerocket imported into the content library, you won’t have to go through this process any more, even for future cluster deployments. That is assuming you don’t delete the content library or the Bottlerocket image.
One last hurdle with the Bottlerocket templating function, the following error will occur:
Validation failed {“validation”: “vsphere Provider setup is valid”, “error”: “failed deploying template: error deploying template: govc: folder ‘/Galleon Datacenter/vm/Templates’ not found\n”, “remediation”: “”}
Error: failed to create cluster: validations failed
This happens because the Bottlerocket templating function is looking for a VM folder named Templates and it doesn’t exist. I mentioned this earlier in the Prerequisite Checklist section. It would appear we were supposed to create a VM folder named Templates right off the Datacenter object. However, I wasn’t able to find this in the documentation. If the create cluster script is supposed to create it, it’s not doing it. The fix is of course to create a VM folder named Templates off the Datacenter object and rerun the script. It should now successfully import the Bottlerocket container image into the content library and then create a template from it which will be used to create the control plane and worker nodes.
A few final thoughts on container images and storage:
- In the end, both Bottlerocket and Ubuntu container images worked in my deployments. The Ubuntu images are much larger in size (Bottlerocket 617MB vs. Ubuntu 4.25GB), thus they consume more storage capacity and take longer to deploy the cluster, particularly on slower storage. Bottlerocket is the default. To use Ubuntu, simply change the osFamily value from bottlerocket to ubuntu in the yaml.
- EKS Anywhere deploys the template to local host storage. For most environments with shared storage, this won’t be a best practice for a variety of reasons. I moved the Bottlerocket and Ubuntu templates from local host storage to shared storage and it didn’t cause an issue with EKS Anywhere. Simply convert the template(s) to VM(s), migrate storage, then convert VM(s) back to template(s). The two essentials tags are maintained throughout the process. Interestingly enough, the content library is created on the same datastore specified in the VSphereMachineConfig section of the yaml which in my case was a shared datastore so no issue with content library storage. I really don’t know why EKS Anywhere was designed to use local host storage for the template(s). Perhaps it was a $/GB savings decision but considering the small amount of capacity each template consumes, especially Bottlerocket at well under 1GB, this wouldn’t make effective sense.
Moving further, the next challenge I ran into was the following error:
Validation failed {“validation”: “vsphere Provider setup is valid”, “error”: “failed setup and validations: provided VSphereMachineConfig sshAuthorizedKey is invalid: ssh: no key found”, “remediation”: “”}
Error: failed to create cluster: validations failed
This error occurs because of the automatically generated sshAuthorizedKeys in the VSphereMachineConfig section of the eksa-cluster.yaml file:
sshAuthorizedKeys:
- ssh-rsa AAAA...
Each of the three instances needs to be changed to the following (note the double quotes):
Performing the above and re-running the script will result in success:
Provided VSphereMachineConfig sshAuthorizedKey is not set or is empty, auto-generating new key pair…
VSphereDatacenterConfig private key saved to prod/eks-a-id_rsa. Use ‘ssh -i prod/eks-a-id_rsa ec2-user@’ to login to your cluster VM
DNS caused problems in one of the labs I was working in. This error is displayed on one or more of the Bottlerocket container image consoles and this error is fatal in that it will halt the deployment of further control plane or worker nodes. This error will also prevent the reporting of a successful deployment to the administrative machine resulting in an unhealthy and dysfunctional EKS Anywhere platform. I used what I learned to recreate the problem in my home lab:
Error deserializing HashMap to Settings: Error deserializing scalar value: Unable to deserialize into ValidLinuxHostname: Invalid hostname ‘WinTest022.boche.lab’: must only be [0-9a-z.-], and 1-253 chars long
The particular lab I was working in leveraged shared DNS infrastructure. Unbeknownst to me, the shared DNS infrastructure had many DNS Reverse Lookup Zone entries with camel case host names. Through troubleshooting this, I learned that Bottlerocket Linux is sensitive to host names and does not tolerate upper case characters. What happens behind the scenes is that each of the control plane and worker nodes receives a DHCP assigned IP address. Bottlerocket performs a reverse lookup on the IP address it receives. Bottlerocket uses the reverse lookup results to construct a host name for itself. If there is no reverse lookup record in DNS, everything works well. However, if the reverse lookup returns a host name with upper case characters, the error above results and the deployment fails. The remedy is to delete stale and unused reverse lookup records, especially those which contain upper case characters. After doing so, re-run the script and all seven control plane and worker nodes should deploy successfully. I do not know if the Ubuntu container image has the same DNS sensitivity that Bottlerocket has.
Sometimes, with all of the above issues addressed and for reasons unknown, the cluster deployment may still fail. In my experience, the first node deploys and powers on. Then the next two nodes deploy and power on. At this point, there is a very long wait and the remaining four nodes do not deploy. After a timeout is reached, the following error is reported on the administrative machine:
Creating new bootstrap cluster
Installing cluster-api providers on bootstrap cluster
Provider specific setup
Creating new workload cluster
Error: failed to create cluster: error waiting for workload cluster control plane to be ready: error executing wait: error: timed out waiting for the condition on clusters/prod
or
Error: failed to create cluster: error waiting for external etcd for workload cluster to be ready: error executing wait: error: timed out waiting for the condition on clusters/prod
Attempting to re-run the deployment script results in further errors because cleanup needs to be performed:
eksctl anywhere create cluster -f eksa-cluster.yaml
Error: failed to create cluster: error creating bootstrap cluster: error executing create cluster: ERROR: failed to create cluster: node(s) already exist for a cluster with the name “prod-eks-a-cluster”
, try rerunning with –force-cleanup to force delete previously created bootstrap cluster
Attempting to re-run the deployment script with the –force-cleanup parameter results in further errors because the –force-cleanup parameter doesn’t actually perform all of the cleanup that is necessary (this is noted in GitHub issue Improve resource cleanup #225):
eksctl anywhere create cluster -f eksa-cluster.yaml –force-cleanup
Error: failed to create cluster: error deleting bootstrap cluster: management cluster in bootstrap cluster
Cleanup is manual at this point. Power off and delete the EKS Anywhere nodes from vSphere inventory. Cleaning up the administrative machine is another matter which at the current time I do not know the correct process for. However, one helpful tip was offered to try at the link above and that is:
kind delete cluster –name prod-eks-a-cluster
Beyond that, the best advice I can offer for cleaning up the administrative machine is to create a snapshot of it just before deploying the EKS Anywhere cluster. If the cluster deployment fails, simply revert to the snapshot. You may now re-run the cluster creation script and keep repeating this process as necessary until the cluster deployment is successful. It can be hit or miss sometimes.
Having worked through each of the errors I encountered, I eventually reached a point where each EKS Anywhere cluster deployment is successful.
administrator@ubuntu-server:~$ eksctl anywhere create cluster -f eksa-cluster.yaml
Performing setup and validations
Warning: VSphereDatacenterConfig configured in insecure mode
✅ Connected to server
✅ Authenticated to vSphere
✅ Datacenter validated
✅ Network validated
✅ Datastore validated
✅ Folder validated
✅ Resource pool validated
✅ Datastore validated
✅ Folder validated
✅ Resource pool validated
✅ Datastore validated
✅ Folder validated
✅ Resource pool validated
✅ Control plane and Workload templates validated
Provided VSphereMachineConfig sshAuthorizedKey is not set or is empty, auto-generating new key pair...
VSphereDatacenterConfig private key saved to prod/eks-a-id_rsa. Use 'ssh -i prod/eks-a-id_rsa ec2-user@<VM-IP-Address>' to login to your cluster VM
✅ Vsphere Provider setup is valid
Creating new bootstrap cluster
Installing cluster-api providers on bootstrap cluster
Provider specific setup
Creating new workload cluster
Installing networking on workload cluster
Installing storage class on workload cluster
Installing cluster-api providers on workload cluster
Moving cluster management from bootstrap to workload cluster
Installing EKS-A custom components (CRD and controller) on workload cluster
Creating EKS-A CRDs instances on workload cluster
Installing AddonManager and GitOps Toolkit on workload cluster
GitOps field not specified, bootstrap flux skipped
Writing cluster config file
Deleting bootstrap cluster
🎉 Cluster created!
administrator@ubuntu-server:~$
This wraps up the challenges for the EKS Anywhere create production cluster deployment. I spent considerably more time working through each of these. The deployment process isn’t bad, but it could use improvement. Namely much better error trapping. The several hoops I had to jump through just to get the Bottlerocket image into to the content library and get a template out of it was mostly nonsense. All of the errors could be anticipated and handled without terminating (and leaving a mess behind). Beefing up documentation around some of these issues encountered would also be helpful.
After a successful EKS Anywhere deployment, I proceeded to deploy a handful of containerized demo applications. William Lam has a number of interesting ones here. Since I hadn’t installed a load balancer yet, I used the Kubernetes NodePort service to make each demo application accessible on the network. I may try tackling an EKS Anywhere external load balancer and ingress controller next. It looks like Kube-Vip and Emissary-ingress come highly recommended.
In closing, I’ll share my eksa-cluster.yaml which can be used for comparison purposes. There really isn’t too much to alter from the default which eksctl creates. Provide information about the vCenter Server address and objects where EKS Anywhere will be deployed, fix the sshAuthorizedKeys, and that’s about it.
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: Cluster
metadata:
name: prod
spec:
clusterNetwork:
cni: cilium
pods:
cidrBlocks:
- 192.168.0.0/16
services:
cidrBlocks:
- 10.96.0.0/12
controlPlaneConfiguration:
count: 2
endpoint:
host: "192.168.110.40"
machineGroupRef:
kind: VSphereMachineConfig
name: prod-cp
datacenterRef:
kind: VSphereDatacenterConfig
name: prod
externalEtcdConfiguration:
count: 3
machineGroupRef:
kind: VSphereMachineConfig
name: prod-etcd
kubernetesVersion: "1.21"
workerNodeGroupConfigurations:
- count: 2
machineGroupRef:
kind: VSphereMachineConfig
name: prod
---
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: VSphereDatacenterConfig
metadata:
name: prod
spec:
datacenter: "Galleon Datacenter"
insecure: true
network: "vlan110"
server: "vc.boche.lab"
thumbprint: ""
---
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: VSphereMachineConfig
metadata:
name: prod-cp
spec:
datastore: "freenas1_nfs_share1"
diskGiB: 25
folder: "eksa"
memoryMiB: 8192
numCPUs: 2
osFamily: bottlerocket
resourcePool: "eksa"
users:
- name: ec2-user
sshAuthorizedKeys:
- ""
---
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: VSphereMachineConfig
metadata:
name: prod
spec:
datastore: "freenas1_nfs_share1"
diskGiB: 25
folder: "eksa"
memoryMiB: 8192
numCPUs: 2
osFamily: bottlerocket
resourcePool: "eksa"
users:
- name: ec2-user
sshAuthorizedKeys:
- ""
---
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: VSphereMachineConfig
metadata:
name: prod-etcd
spec:
datastore: "freenas1_nfs_share1"
diskGiB: 25
folder: "eksa"
memoryMiB: 8192
numCPUs: 2
osFamily: bottlerocket
resourcePool: "eksa"
users:
- name: ec2-user
sshAuthorizedKeys:
- ""
---