 At 9am PDT this morning, Paul Maritz and Steve Herrod take the stage to announce the next generation of the VMware virtualized datacenter. Each new product and set of features are impressive in their own right. Combine them and what you have is a major upgrade of VMware’s entire cloud infrastructure stack. I’ll highlight the major announcements and some of the detail behind them. In addition, the embargo and NDA surrounding the vSphere 5 private beta expires. If you’re a frequent reader of blogs or the Twitter stream, you’re going to bombarded with information at fire-hose-to-the-face pace, starting now.
At 9am PDT this morning, Paul Maritz and Steve Herrod take the stage to announce the next generation of the VMware virtualized datacenter. Each new product and set of features are impressive in their own right. Combine them and what you have is a major upgrade of VMware’s entire cloud infrastructure stack. I’ll highlight the major announcements and some of the detail behind them. In addition, the embargo and NDA surrounding the vSphere 5 private beta expires. If you’re a frequent reader of blogs or the Twitter stream, you’re going to bombarded with information at fire-hose-to-the-face pace, starting now.

vSphere 5.0 (ESXi 5.0 and vCenter 5.0)
At the heart of it all is a major new release of VMware’s type 1 hypervisor and management platform. Increased scalability and new features make virtualizing those last remaining tier 1 applications quantifiable.


ESX and the Service Console are formally retired as of this release. Going forward, we have just a single hypervisor to maintain and that is ESXi. Non-Windows shops should find some happiness in a Linux based vCenter appliance and sophisticated web client front end. While these components are not 100% fully featured yet in their debut, they come close.
Storage DRS is the long awaited compliment to CPU and memory based DRS introduced in VMware Virtual Infrastructure 3. SDRS will coordinate initial placement of VM storage in addition to keeping datastore clusters balanced (space usage and latency thresholds including SIOC integration) with or without the use of SDRS affinity rules. Similar to DRS clusters, SDRS enabled datastore clusters offer maintenance mode functionality which evacuates (Storage vMotion or cold migration) registered VMs and VMDKs (still no template migration support, c’mon VMware) off of a datastore which has been placed into maintenance mode. VMware engineers recognize the value of flexibility, particularly when it comes to SDRS operations where thresholds can be altered and tuned on a schedule basis. For instance, IO patterns during the day when normal or peak production occurs may differ from night time IO patterns when guest based backups and virus scans occur. When it comes to SDRS, separate thresholds would be preferred so that SDRS doesn’t trigger based on inappropriate thresholds.
Profile-Driven Storage couples storage capabilities (VASA automated or manually user-defined) to VM storage profile requirements in an effort to meet guest and application SLAs. The result is the classification of a datastore, from a guest VM viewpoint, of Compatible or Incompatible at the time of evaluating VM placement on storage. Subsequently, the location of a VM can be automatically monitored to ensure profile compliance.
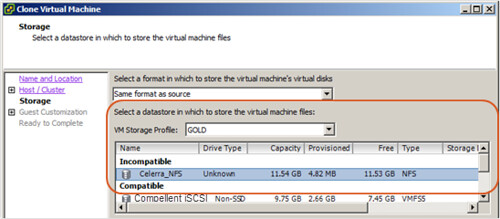
 I mentioned VASA previously which is a new acronym for vSphere Storage APIs for Storage Awareness. This new API allows storage vendors to expose topology, capabilities, and state of the physical device to vCenter Server management. As mentioned earlier, this information can be used to automatically populate the capabilities attribute in Profile-Driven Storage. It can also be leveraged by SDRS for optimized operations.
I mentioned VASA previously which is a new acronym for vSphere Storage APIs for Storage Awareness. This new API allows storage vendors to expose topology, capabilities, and state of the physical device to vCenter Server management. As mentioned earlier, this information can be used to automatically populate the capabilities attribute in Profile-Driven Storage. It can also be leveraged by SDRS for optimized operations.
The optimal solution is to stack the functionality of SDRS and Profile-Driven Storage to reduce administrative burden while meeting application SLAs through automated efficiency and optimization.
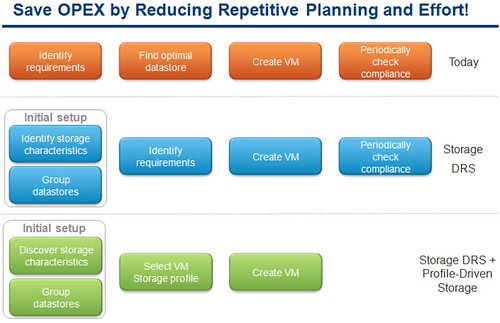
 If you look closely at all of the announcements being made, you’ll notice there is only one net-new release and that is the vSphere Storage Appliance (VSA). Small to medium business (SMB) customers are the target market for the VSA. These are customers who seek some of the enterprise features that vSphere offers like HA, vMotion, or DRS but lack the fibre channel SAN, iSCSI, or NFS shared storage requirement. A VSA is deployed to each ESXi host which presents local RAID 1+0 host storage as NFS (no iSCSI or VAAI/SAAI support at GA release time). Each VSA is managed by one and only one vCenter Server. In addition, each VSA must reside on the same VLAN as the vCenter Server. VSAs are managed by the VSA Manager which is a vCenter plugin available after the first VSA is installed. It’s function is to assist in deploying VSAs, automatically mounting NFS exports to each host in the cluster, and to provide monitoring and troubleshooting of the VSA cluster.
If you look closely at all of the announcements being made, you’ll notice there is only one net-new release and that is the vSphere Storage Appliance (VSA). Small to medium business (SMB) customers are the target market for the VSA. These are customers who seek some of the enterprise features that vSphere offers like HA, vMotion, or DRS but lack the fibre channel SAN, iSCSI, or NFS shared storage requirement. A VSA is deployed to each ESXi host which presents local RAID 1+0 host storage as NFS (no iSCSI or VAAI/SAAI support at GA release time). Each VSA is managed by one and only one vCenter Server. In addition, each VSA must reside on the same VLAN as the vCenter Server. VSAs are managed by the VSA Manager which is a vCenter plugin available after the first VSA is installed. It’s function is to assist in deploying VSAs, automatically mounting NFS exports to each host in the cluster, and to provide monitoring and troubleshooting of the VSA cluster.
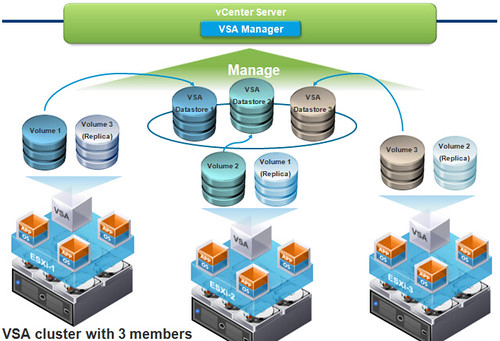
 You’re probably familiar with the concept of a VSA but at this point you should start to notice the differences in VMware’s VSA: integration. In addition, it’s a VMware supported configuration with “one throat to choke” as they say. Another feature is resiliency. The VSAs on each cluster node replicate with each other and if required will provide seamless fault tolerance in the event of a host node failure. In such a case, a remaining node in the cluster will take over the role of presenting a replica of the datastore which went down. Again, this process is seamless and is accomplished without any change in the IP configuration of VMkernel ports or NFS exports. With this integration in place, it was a no-brainer for VMware to also implement maintenance mode for VSAs. MM comes in to flavors: Whole VSA cluster MM or Single VSA node MM.
You’re probably familiar with the concept of a VSA but at this point you should start to notice the differences in VMware’s VSA: integration. In addition, it’s a VMware supported configuration with “one throat to choke” as they say. Another feature is resiliency. The VSAs on each cluster node replicate with each other and if required will provide seamless fault tolerance in the event of a host node failure. In such a case, a remaining node in the cluster will take over the role of presenting a replica of the datastore which went down. Again, this process is seamless and is accomplished without any change in the IP configuration of VMkernel ports or NFS exports. With this integration in place, it was a no-brainer for VMware to also implement maintenance mode for VSAs. MM comes in to flavors: Whole VSA cluster MM or Single VSA node MM.
VMware’s VSA isn’t a freebie. It will be licensed. The figure below sums up the VSA value proposition:

High Availability (HA) has been enhanced dramatically. Some may say the version shipping in vSphere 5 is a complete rewrite. What was once foundational Legato AAM (Automated Availability Manager) is now finally evolving to scale further with vSphere 5. Some of the new features include elimination of common issues such as DNS resolution, node communication between management network as well as storage along with failure detection enhancement. IPv6 support, consolidated logging into one file per host, enhanced UI and enhanced deployment mechanism (as if deployment wasn’t already easy enough, albeit sometimes error prone).
 From an architecture standpoint, HA has changed dramatically. HA has effectively gone from five (5) fail over coordinator hosts to just one (1) in a Master/Slave model. No more is there a concept of Primary/Secondary HA hosts, however if you still want to think of it that way, it’s now one (1) primary host (the master) and all remaining hosts would be secondary (the slaves). That said, I would consider it a personal favor if everyone would use the correct version specific terminology – less confusion when assumptions have to be made (not that I like assumptions either, but I digress).
From an architecture standpoint, HA has changed dramatically. HA has effectively gone from five (5) fail over coordinator hosts to just one (1) in a Master/Slave model. No more is there a concept of Primary/Secondary HA hosts, however if you still want to think of it that way, it’s now one (1) primary host (the master) and all remaining hosts would be secondary (the slaves). That said, I would consider it a personal favor if everyone would use the correct version specific terminology – less confusion when assumptions have to be made (not that I like assumptions either, but I digress).
The FDM (fault domain manager) Master does what you traditionally might expect: monitors and reacts to slave host & VM availability. It also updates its inventory of the hosts in the cluster, and the protected VMs each time a VM power operation occurs.
Slave hosts have responsibilities as well. They maintain a list of powered on VMs. They monitor local VMs and forward significant state changes to the Master. They provide VM health monitoring and any other HA features which do not require central coordination. They monitor the health of the Master and participate in the election process should the Master fail (the host with the most datastores and then the lexically highest moid [99>100] wins the election).
Another new feature in HA the ability to leverage storage to facilitate the sharing of stateful heartbeat information (known as Heartbeat Datastores) if and when management network connectivity is lost. By default, vCenter picks two datastores for backup HA communication. The choices are made by how many hosts have connectivity and if the storage is on different arrays. Of course, a vSphere administrator may manually choose the datastores to be used. Hosts manipulate HA information on the datastore based on the datastore type. On VMFS datastores, the Master reads the VMFS heartbeat region. On NFS datastores, the Master monitors a heartbeat file that is periodically touched by the Slaves. VM availability is reported by a file created by each Slave which lists the powered on VMs. Multiple Master coordination is performed by using file locks on the datastore.
As discussed earlier, there are a number of GUI enhancements which were put in place to monitor and configure HA in vSphere 5. I’m not going to go into each of those here as there are a number of them. Surely there will be HA deep dives in the coming months. Suffice it to say, they are all enhancements which stack to provide ease of HA management, troubleshooting, and resiliency.
Another significant advance in vSphere 5 is Auto Deploy which integrates with Image Builder, vCenter, and Host Profiles. The idea here is centrally managed stateless hardware infrastructure. ESXi host hardware PXE boots an image profile from the Auto Deploy server. Unique host configuration is provided by an answer file or VMware Host Profiles (previously an Enterprise Plus feature). Once booted, the host is added to vCenter host inventory. Statelessness is not necessarily a newly introduced concept, therefore, the benefits are strikingly familiar to say ESXi boot from SAN: No local boot disk (right sized storage, increased storage performance across many spindles), scales to support of many hosts, decoupling of host image from host hardware – statelessness defined. It may take some time before I warm up to this feature. Honestly, it’s another vCenter dependency, this one quite critical with the platform services it provides.
For a more thorough list of anticipated vSphere 5 “what’s new” features, take a look at this release from virtualization.info.
vCloud Director 1.5
 Up next is a new release of vCloud Director version 1.5 which marks the first vCD update since the product became generally available on August 30th, 2010. This release is packed with several new features.
Up next is a new release of vCloud Director version 1.5 which marks the first vCD update since the product became generally available on August 30th, 2010. This release is packed with several new features.
Fast Provisioning is the space saving linked clone support missing in the GA release. Linked clones can span multiple datastores and multiple vCenter Servers. This feature will go a long way in bridging the parity gap between vCD and VMware’s sun setting Lab Manager product.
3rd party distributed switch support means vCD can leverage virtualized edge switches such as the Cisco Nexus 1000V.
The new vCloud Messages feature connects vCD with existing AMQP based IT management tools such as CMDB, IPAM, and ticketing systems to provide updates on vCD workflow tasks.
vCD originally supported Oracle 10g std/ent Release 2 and 11g std/ent. vCD now supports Microsoft SQL Server 2005 std/ent SP4 and SQL Server 2008 exp/std/ent 64-bit. Oracle 11g R2 is now also supported. Flexibility. Choice.
vCD 1.5 adds support for vSphere 5 including Auto Deploy and virtual hardware version 8 (32 vCPU and 1TB vRAM). In this regard, VMware extends new vSphere 5 scalability limits to vCD workloads. Boiled down: Any tier 1 app in the private/public cloud.
Last but not least, vCD integration with vShield IPSec VPN and 5-tuple firewall capability.
vShield 5.0
VMware’s message about vShield is that it has become a fundamental component in consolidated private cloud and multi-tenant VMware virtualized datacenters. While traditional security infrastructure can take significant time and resources to implement, there’s an inherent efficiency in leveraging security features baked into and native to the underlying hypervisor.
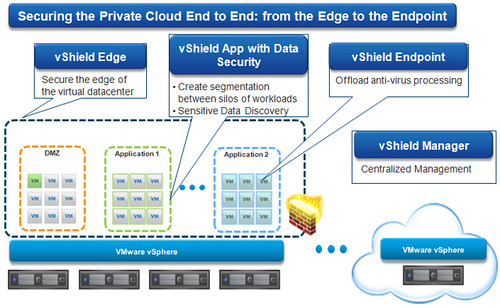
There are no changes in vShield Endpoint, however, VMware has introduced static routing in vShield Edge (instead of NAT) for external connections and certificate-based VPN connectivity.
Site Recovery Manager 5.0
 Another major announcement from VMware is the introduction of SRM 5.0. SRM has already been quite successful in providing simple and reliable DR protection for the VMware virtualized datacenter. Version 5 boasts several new features which enhance functionality.
Another major announcement from VMware is the introduction of SRM 5.0. SRM has already been quite successful in providing simple and reliable DR protection for the VMware virtualized datacenter. Version 5 boasts several new features which enhance functionality.
Replication between sites can be achieved in a more granular per-VM (or even sub-VM) fashion, between different storage types, and it’s handled natively by vSphere Replication (vSR). More choice in seeding of the initial full replica. The result is a simplified RPO.
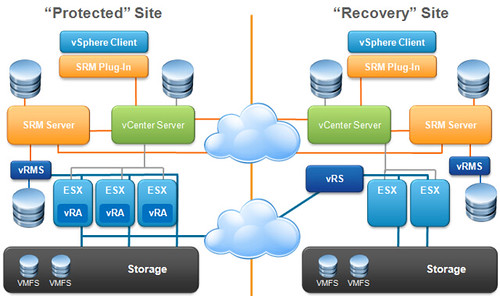
Another new feature in SRM is Planned Migration which facilitates the migration protected VMs from site to site before a disaster actually occurs. This could also be used in advance of datacenter maintenance. Perhaps your policy is to run your business 50% of the time from the DR site. The workflow assistance makes such migrations easier. It’s a downtime avoidance mechanism which makes it useful in several cases.
 Failback can be achieved once the VMs are re protected at the recovery site and the replication flow is reversed. It’s simply another push of the big button to go the opposite direction.
Failback can be achieved once the VMs are re protected at the recovery site and the replication flow is reversed. It’s simply another push of the big button to go the opposite direction.
Feedback from customers has influenced UI enhancements. Unification of sites into one GUI is achieved without Linked Mode or multiple vSphere Client instances. Shadow VMs take on a new look at the recovery site. Improved reporting for audits.
Other miscellaneous notables are IPv6 support, performance increase in guest VM IP customization, ability to execute scripts inside the guest VM (In guest callouts), new SOAP based APIs on the protected and recovery sides, and a dependency hierarchy for protected multi tiered applications.
In summary, this is a magnificent day for all of VMware as they have indeed raised the bar with their market leading innovation. Well done!
VMware product diagrams courtesy of VMware
Star Wars diagrams courtesy of Wookieepedia, the Star Wards Wiki
















Well done!
This was a very helpful overview of a broad announcement. Thanks Jason for putting it together! I also enjoyed the Star Wars techno-grams 🙂
To me, the most interesting development is SDRS and what the eventual trajectory is going to be for this branch of virtualization technology. It looks like it has the fundamental capabilities for storage tiering, but it doesn’t need to perform real time sub-LUN relocation to be incredibly useful. A lot of customers will find maintenance mode to be extremely useful, I’m sure – if for no other reason than it removes human error from doing what it does so well at the worst possible times.
Very exciting, and thanks again for an excellent roundup.
Jason,
HA looks a lot different but the ramifications out side of where all the logs are don’t seem as bad as some of the other changes.
#1: Licensing changes will become a design consideration.
#2: New CLI to replace both Esxcfg (Retired) and vShpere 4 CLI.
Yes it’s great to be unifing the CLI sturcture but I been hitting the DCA so hard it’s going to make my head spin. 🙂
Over all this looks to be great step forward. Looking forward to working with SDRS and VSANs.
Excellnet Job Jason..
Unless I’m not understanding this right, I’m going to have to purchase more licenses than I currently have just to work with this vRAM licensing scheme. So on top of having a license per socket, I will need additional licenses just to reach the vRAM amount I need.
Very nice write up. I especially like the Star Wars schematics on the side to put things into prospective.