For me, it’s hard to believe nearly a year has elapsed since vSphere 5 was announced on July 12th. Among the many new features that shipped was an added 4th VAAI primitive for block storage. The primitive itself revolved around thin provisioning and was the sum of two components: UNMAP and STUN. At this time I’m going to go through the UNMAP/Block Space Reclamation process in a lab environment and I’ll leave STUN for a later discussion.
Before I jump into the lab, I want frame out a bit of a chronological timeline around the new primitive. Although this 4th primitive was formally launched with vSphere 5 and built into the corresponding platform code that shipped, a few months down the road VMware issued a recall on the UNMAP portion of the primitive due to a discovery made either in the field or in their lab environment. With the UNMAP component recalled, the Thin Provisioning primitive as a whole (including the STUN component) was not supported by VMware. Furthermore, storage vendors could not be certified for the Thin Provisioning VAAI primitive although the features may have been functional if their respective arrays supported it. A short while later, VMware released a patch which, once installed on the ESXi hosts, disabled the UNMAP functionality globally. In March of this year, VMware released vSphere 5.0 Update 1. With this release, VMware implemented the necessary code to resolve the performance issues related to UNMAP. However, VMware did not re-enable the automatic UNMAP mechanism. Instead and in the interim, VMware implemented a manual process for block space reclamation on a per datastore basis regardless of the global UNMAP setting on the host. I believe it is VMware’s intent to bring back “automatic” UNMAP long term but that is purely speculation. This article will walk through the manual process of returning unused blocks to a storage array which supports both thin provisioning and the UNMAP feature.
I also want to point out some good information that already exists on UNMAP which introduces the feature and provides a good level of detail.
- Duncan Epping wrote this piece about a year ago when the feature was launched.
- Cormac Hogan wrote this article in March when vSphere 5.0 Update 1 was launched and the manual UNMAP process was re-introduced.
- VMware KB 2014849 Using vmkfstools to reclaim VMFS deleted blocks on thin-provisioned LUNs
By this point, if you are unaware of the value of UNMAP, it is simply keeping thin provisioned LUNs thin. By doing so, raw storage is consumed and utilized in the most efficient manner yielding cost savings and better ROI for the business. Arrays which support thin provisioning have been shipping for years. What hasn’t matured is just as important as thin provisioning itself: the ability to stay thin where possible. I’m going to highlight this below in a working example but basically once pages are allocated from a storage pool, they remain pinned to the volume they were originally allocated for, even after the data written to those pages has been deleted or moved. Once the data is gone, the free space remains available to that particular LUN and the storage host which owns it and will continue to manage it – whether or not that free space will ever be needed again in the future for that storage host. Without UNMAP, the pages are never released back to the global storage pool where they may be allocated to some other LUN or storage host whether it be virtual or physical. Ideal use cases for UNMAP: Transient data, Storage vMotion, SDRS, data migration. UNMAP functionality requires the collaboration of both operating system and storage vendors. As an example, Dell Compellent Storage Center has supported the T10 UNMAP command going back to early versions of the 5.x Storage Center code, however there has been very little adoption on the OS platform side which is responsible for issuing the UNMAP command to the storage array when data is deleted from a volume. RHEL 6 supports it, vSphere 5.0 Update 1 now supports it, and Windows Server 2012 is slated to be the first Windows platform to support UNMAP.
UNMAP in the Lab
So in the lab I have a vSphere ESXi 5.0 Update 1 host attached to a Dell Compellent Storage Center SAN. To demonstrate UNMAP, I’ll Storage vMotion a 500GB virtual machine from one 500GB LUN to another 500GB LUN. As you can see below from the Datastore view in the vSphere Client, the 500GB VM is already occupying lun1 and an alarm is thrown due to lack of available capacity on the datastore:

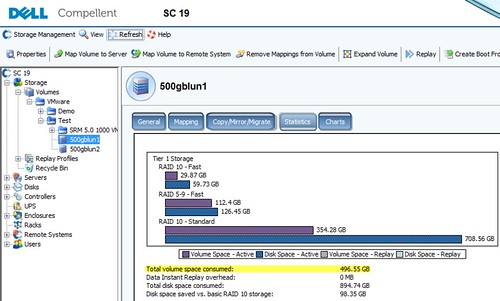
Looking at the volume in Dell Compellent Storage Center, I can see that approximately 500GB of storage is being consumed from the storage page pool. To keep the numbers simple, I’ll ignore actual capacity consumed due to RAID overhead.
After the Storage vMotion
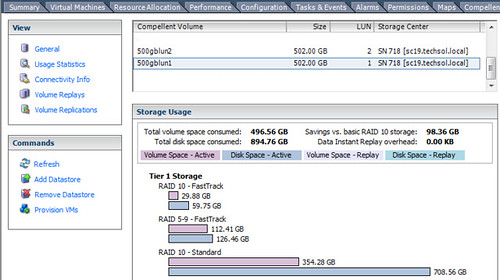
I’ve now performed a Storage vMotion of the 500GB VM from lun1 to lun2. Again looking at the datastores from a vSphere client perspective, I can see that lun2 is now completely consumed with data while lun1 is no longer occupied – it now has 500GB capacity available. This is where operating systems and storage arrays which do not support UNMAP fall short of keeping a volume thin provisioned.

Using the Dell Compellent vSphere Client plug-in, I can see that the 500GB of raw storage originally allocated for lun1 remains pinned with lun1 even though the LUN is empty! I’m also occupying 500GB of additional storage for the virtual machine now residing on lun2. The net here is that as a result of my Storage vMotion, I’m occupying nearly 1TB of storage capacity for a virtual machine that’s half the size. If I continue to Storage vMotion this virtual machine to other LUNs, the problem is compounded and the available capacity in the storage pool continues to drain, effectively raising the high watermark of consumed storage. To add insult to injury, this will more than likely be stranded Tier 1 storage – backed by the most expensive spindles in the array.
Performing the Manual UNMAP
Using a PuTTY connection to the ESXi host, I’ll start with identifying the naa ID of my datastore using esxcli storage core device list |more

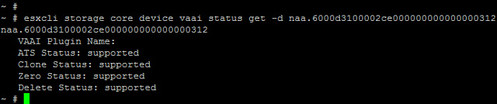
Following the KB article above, I’ll make sure my datastore supports the UNMAP primitive using esxcli storage core device vaai status get -d <naa ID>. The output shows UNMAP is supported by Dell Compellent Storage Center, in addition to the other three core VAAI primitives (Atomic Test and Set, Copy Offload, and Block Zeroing).
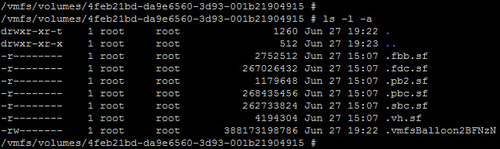
I’ll now change to the directory of the datastore and perform the UNMAP using vmkfstools -y 100. It’s worth pointing out here that using a value of 100, although apparently supported, ultimately fails. I reran the command using a value of 99% which successfully unmapped 500GB in about 3 minutes.

Also important to note is VMware recommends the reclaim be run after hours or during a maintenance window with maximum recommended reclaim percentage of 60%. This value is pointed out by Duncan in the article I linked above and it’s also noted when providing a reclaim value outside of the acceptable parameters of 0-100. Here’s the reasoning behind the value: When the manual UNMAP process is run, it balloons up a temporary hidden file at the root of the datastore which the UNMAP is being run against. You won’t see this balloon file with the vSphere Client’s Datastore Browser as it is hidden. You can catch it quickly while UNMAP is running by issuing the ls -l -a command against the datastore directory. The file will be named .vmfsBalloon along with a generated suffix. This file will quickly grow to the size of data being unmapped (this is actually noted when the UNMAP command is run and evident in the screenshot above). Once the UNMAP is completed, the .vmfsBalloon file is removed. For a more detailed explanation behind the .vmfsBalloon file, check out this blog article.
The bottom line is that the datastore needs as much free capacity as what is being unmapped. VMware’s recommended value of 60% reclaim is actually a broad assumption that the datastore will have at least 60% capacity available at the time UNMAP is being run. For obvious reasons, we don’t want to run the datastore out of capacity with the .vmfsBalloon file, especially if there are still VMs running on it. My recommendation if you are unsure or simply bad at math: start with a smaller percentage of block reclaim initially and perform multiple iterations of UNMAP safely until all unused blocks are returned to the storage pool.
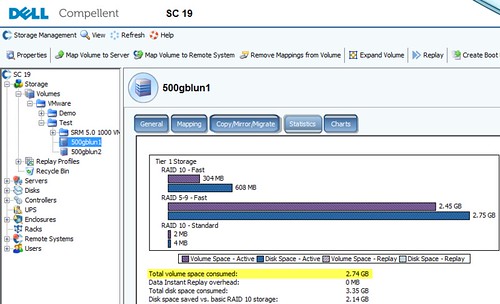
To wrap up this procedure, after the UNMAP step has been run with a value of 99%, I can now see from Storage Center that nearly all pages have been returned to the page pool and 500gbvol1 is only consuming a small amount of raw storage comparatively – basically the 1% I wasn’t able to UNMAP using the value of 99% earlier. If I so chose, I could run the UNMAP process again with a value of 99% and that should return just about all of the 2.74GB still being consumed, minus the space consumed for VMFS-5 formatting.
The last thing I want to emphasize is that today, UNMAP works at the VMFS datastore layer and isn’t designed to work inside the encapsulated virtual machine. In other words, if I delete a file inside a guest operating system running on top of the vSphere hypervisor with attached block storage, that space can’t be liberated with UNMAP. As a vSphere and storage enthusiast, for me that would be next on the wish list and might be considered by others as the next logical step in storage virtualization. And although UNMAP doesn’t show up in Windows platforms until 2012, Dell Compellent has developed an agent which accomplishes the free space recovery on earlier versions of Windows in combination with a physical raw device mapping (RDM).
Update 7/2/12: VMware Labs released its latest fling – Guest Reclaim.
From labs.vmware.com:
Guest Reclaim reclaims dead space from NTFS volumes hosted on a thin provisioned SCSI disk. The tool can also reclaim space from full disks and partitions, thereby wiping off the file systems on it. As the tool deals with active data, please take all precautionary measures understanding the SCSI UNMAP framework and backing up important data.
Features
- Reclaim space from Simple FAT/NTFS volumes
- Works on WindowsXP to Windows7
- Can reclaim space from flat partitions and flat disks
- Can work in virtual as well as physical machines
Whats a Thin provisioned (TP) SCSI disks? In a thin provisioned LUN/Disk, physical storage space is allocated on demand. That is, the storage system allocates space as and when a client (example a file system/database) writes data to the storage medium. One primary goal of thin provisioning is to allow for storage overcommit. A thin provisioned disk can be a virtual disk, or a physical LUN/disk exposed from a storage array that supports TP. Virtual disks created as thin disks are exposed as TP disks, starting with virtual Hardware Version 9. For more information on this please refer http://en.wikipedia.org/wiki/Thin_provisioning. What is Dead Space Reclamation?Deleting files frees up space on the file system volume. This freed space sticks with the LUN/Disk, until it is released and reclaimed by the underlying storage layer. Free space reclamation allows the lower level storage layer (for example a storage array, or any hypervisor) to repurpose the freed space from one client for some other storage allocation request. For example:
- A storage array that supports thin provisioning can repurpose the reclaimed space to satisfy allocation requests for some other thin provisioned LUN within the same array.
- A hypervisor file system can repurpose the reclaimed space from one virtual disk for satisfying allocation needs of some other virtual disk within the same data store.
GuestReclaim allows transparent reclamation of dead space from NTFS volumes. For more information and detailed instructions, view the Guest Reclaim ReadMe (pdf)
Update 5/14/13: Excerpt from Cormac Hogan’s vSphere storage blog: “We’ve recently been made aware of a limitation on our UNMAP mechanism in ESXi 5.0 & 5.1. It would appear that if you attempt to reclaim more than 2TB of dead space in a single operation, the UNMAP primitive is not handling this very well.” Read more about it here: Heads Up! UNMAP considerations when reclaiming more than 2TB s
Update 9/13/13: vSphere 5.5 UNMAP Deep Dive
















According to Microsoft, Hyper-V 3.0 shipping in Server 2012 will support UNMAP, and also Windows Server 2012 will be TRIM aware. So from the OS through to the Hypervisor with the MS stack it will fully support dead space reclaimation. Hopefully VMware can catch up and turn the feature back on in a future update, and support WS 2012 TRIM guest commands.
VMware needs to fully automate this. Percentage of people that know of this and are actually using it is probably small. Not only that but if you have other VM’s on the lun as you point out, you now have to worry about filling up the Datastore and other VMs not being able to write to it and that is IF you are up to date with your storage software and vmware software to make this work. The other option is to delete, move and recreate your Datastores and to do that you really need to go a Datastore per VM so you don’t have to move VM’s every minute if you are deleting one VM. All of this VMware needs to address with Storage Vendors.
Hi. What about fully allocated LUNs? Usage metrics between datastore and LUN (storage view) will differ when tasks like svmotion, deletions, etc take place. Will this “hole punching” also work for full allocated LUNs?
I understand how UNMAP helps to keep thin LUNs thin. I understand that a fully allocated LUN means guaranteed space from the storage side and moves/deletions from a fully allocated LUN still means that LUN’s allocated space from the storage will not change. I would just like to have a better representation of what my actual LUN usage is when I do moves/deletions from the ESXi side.
Here’s a link that discusses what I’m talking about:
https://communities.netapp.com/thread/15549
You can see that the NetApp plugin reports differences in what the datastore reports, and what the storage reports. This is with a fully allocated LUN.
@forbsy UNMAP is going to return any unused blocks or pages from a thin provisioned LUN back to the storage pool. If the LUN is not thin provisioned, then this primitive doesn’t apply as it is only geared towards thin provisioned LUNs.
Bummer. I guess the discrepentcy between the storage view and the datastore view for fully provisioned LUNs persists.
Thanks Jason for yet another informative article. I never knew that claimed space is never released. Makes perfect sense though when thinking about it and reading this article explains it perfectly.
N.B. Please note the first comment added to this article is spam =)
Thanks Yuri – got rid of that spam comment which slipped through the filters 🙂