It has previously been announced that VMware’s Distributed Power Management (DPM) technology will be fully supported in vSphere. Although today DPM is for experimental purposes only, virtual infrastructure users with VI Enterprise licensing can nonetheless leverage its usefulness of powering down ESX infrastructure during non-peak periods where they see fit.
Before enabling DPM, there are a few precautionary steps I would go through first to test each ESX host in the cluster for DPM compatibility which will help mitigate risk and ensure success. Assuming most, if not all, hosts in the cluster will be identical in hardware make and model, you may choose to perform these tests on only one of the hosts in the cluster. More on testing scope a little further down.
This first step is optional but personally I’d go through the motions anyway. Remove the hosts to be tested individually from the cluster. If the hosts have running VMs, place the host in maintenance mode first to displace the running VMs onto other hosts in the cluster:
If the step above was skipped or if the host wasn’t in a cluster to begin with, then the first step is to place the clustered host into maintenance mode. The following step would be to manually place the host in Standby Mode. This is going to validate whether or not vCenter can successfully place a host into Standby Mode automatically when DPM is enabled. One problem I’ve run into is the inability to place a host into Standby Mode because the NIC doesn’t support Wake On LAN (WOL) or WOL isn’t enabled on the NIC:

Assuming the host has successfully been place into Standby Mode, use the host command menu (similar in look to the menu above) to take the host out of Standby Mode. I don’t have the screen shot for that because the particular hosts I’m working with right now aren’t supporting the WOL type that VMware needs.
Once the host has successfully entered and left Standby Mode, the it can be removed from maintenance mode and added back into the cluster. Now would not be a bad time to take a look around some of the key areas such as networking and storage to make sure those subsystems are functioning properly and they are able to “see” their respective switches, VLANs, LUNs, etc. Add some VMs to the host and power them on. Again, perform some cursory validation to ensure the VMs have network connectivity, storage, and the correct consumption of CPU and memory.
My point in all of this is that ESX has been brought back from a deep slumber. A twelve point health inspection is the least amount of effort we can put forth on the front side to assure ourselves that, once automated, DPM will not bite us down the road. The steps I’m recommending have more to do with DPM compatibility with the different types of server and NIC hardware, than they have to do with VMware’s DPM technology in and of itself. That said, at a minimum I’d recommend these preliminary checks on each of the different hardware types in the datacenter. On the other end of the spectrum if you are very cautious, you may choose to run through these steps for each and every host that will participate in a DPM enabled cluster.
After all the ESX hosts have been “Standby Mode verified”, the cluster settings can be configured to enable DPM. Similar to DRS, DPM can be enabled in a manual mode where it will make suggestions but it won’t act on them without your approval, or it can be set for fully automatic, dynamically making and acting on its own decisions:
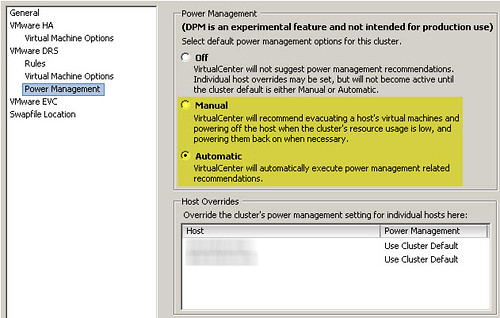
DPM is an interesting technology but I’ve always felt in the back of my mind it conflicts with capacity planning (including the accounting for N+1 or N+2, etc.) and the ubiquitous virtualization goal of maximizing the use of server infrastructure. In a perfect world, we’ll always be teetering on our own perfect threshold of “just enough infrastructure” and “not too much infrastructure”. Having infrastructure in excess of what what would violate availability constraints and admission control is where DPM fits in. That said, if you have a use for DPM, in theory, you have excess infrastructure. Why? I can think of several compelling reasons why this might happen, but again in that perfect world, none could excuse the capital virtualization sin of excess hardware not being utilized to its fullest potential (let alone, powered off and doing nothing). In a perfect world, we always have just enough hardware to meet cyclical workload peaks but not too much during the valleys. In a perfect world, virtual server requests come planned so well in advance that any new infrastructure needed is added the day the VM is spun up to maintain that perfect balance. In a perfect world, we don’t purchase larger blocks or cells of infrastructure than what we actually need because there are no such things as lead times for channel delivery, change management, and installation that we need to account for.
If you don’t live in a perfect world (like me), DPM offers those of us with an excess of infrastructure and excuses an environment friendly and responsible alternative to at least cut the consumption of electricity and cooling while maintaining capacity on demand if and when needed. Options and flexibility through innovation is good. That is why I choose VMware.
















Hi Jason,
How will virtual center & my monitoring solutions know the difference between a Host that has been powered down via DPM and a Host that has fallen over?
@Chris: Today, there is no distinguishable difference between a host that has gracefully been shut down, placed in standby mode, or as you put it has “fallen over”. This question was asked in a DPM session at VMworld 2008 in Vegas. Actually, I think I’m the one that asked it – I’ll see if I can dig up the video for that. At any rate, VMware didn’t have the technology at the time to address the question. I can’t say what will be embedded in vSphere. I will say that external/3rd party monitoring and change management systems will still apply though and you’ll need to figure out how those systems account for the (dynamically) planned outage/change. Many shops struggled to wrap a change management process around VMotion and even more so, fully automated DRS. A big difference being there though that VMotion and DRS results in no visible outage, whereas DPM does. If VMware has any brains at all, they’ll at least figure out how to allow vCenter Server to account for a DPM outage such that it DOES NOT fire alerts/alarms for a host outage that it planned and executed itself. If vCenter has this intelligence and your 3rd party monitoring solution ties into vCenter APIs or SNMP traps, then your mostly set but you’ll still need to deal with the change management piece.
I thought as much 🙂
tying maintenance mode in vcenter with maintnenace mode in MOM/SCOM ( via Nworks/Veeam ) would be a good start to this.
Hello!
Very Interesting post! Thank you for such interesting resource!
PS: Sorry for my bad english, I’v just started to learn this language 😉
See you!
Your, Raiul Baztepo
A use case for DPM not mentioned in the post is DR hot-sites. In a colo facility where you pay for actual power consumption, DPM represents a significant cost saving opportunity.
Note that DPM in vSphere also supports the IPMI/iLO BMC connections offered on most enterprise class hardware as well as WoL.
See page 61:
http://www.vmware.com/pdf/vsphere4/r40/vsp_40_resource_mgmt.pdf
I see DPM being useful for enterprises whose peak workload (eg mon-fri 9am-5pm) is significantly higher than off-peak workload, so they need more resource during the business hours than out of business hours.
However, I also see the following happening:
Out of hours DPM powers off one of the VMware ESX hosts, a VMware administrator then brings a further VMware ESX host into maintenance mode to do some patching, and boom, just in that instant a further VMware ESX host fails. Suddenly you don’t have enough capacity to power up all your VMs from the failed host. By the time DPM powers up the powered off host your entire VMware cluster has slown to a complete crawl.
I think I’m gonna wait and see feedback on others mileage with DPM before I look to implement.
Just use the DPM slider people, it negates all your capacity worries.