If you ended up here searching for information on PDL or APD, your evening or weekend plans may be cancelled at this point and I’m sorry for you if that is the case. There are probably 101 or more online resources which discuss the interrelated vSphere storage topics of All Paths Down (known as APD), Permanent Device Loss (known as PDL), and vSphere High Availability (known as HA, and before dinosaurs roamed the Earth – DAS ). To put it in perspective, I’ve quickly pulled together a short list of resources below using Google. I’ve read most of them:
VMware KB: Permanent Device Loss (PDL) and All-Paths …
VMware KB: PDL AutoRemove feature in vSphere 5.5
Handling the All Paths Down (APD) condition – VMware Blogs
vSphere 5.5. Storage Enhancements Part 9 – PDL …
Permanent Device Loss (PDL) enhancements in vSphere 5.0
APD (All Paths Down) and PDL (Permanent Device Loss …
vSphere Metro Storage Cluster solutions and PDL’s …
vSphere Metro Stretched Cluster with vSphere 5.5 and PDL …
Change in Permanent Device Loss (PDL) behavior for 5.1 …
VMware KB: PDL AutoRemove feature in vSphere 5.5
PDL AutoRemove – CormacHogan.com
How handle the APD issue in vSphere – vInfrastructure Blog
Interpreting SCSI sense codes in VMware ESXi and ESX
What’s New in VMware vSphere® 5.1 – Storage
vSphere configuration for handling APD/PDL … – CloudXC
vSphere 5.1 Storage Enhancements – Part 4: All Paths Down
vSphere 5.5 nuggets: changes to disk … – Yellow Bricks
ESXi host disk.terminateVMOnPDLDefault configuration …
ESXi host VMkernel.Boot.terminateVMOnPDL configuration
vSphere HA in my opinion is a great feature. It has saved my back side more than once both in the office and at home. Several books have been more or less dedicated to the topic and yet it is so easy to use that an entire cluster and all of its running virtual machines can be protected with default parameters (common garden variety) with just two mouse clicks.
VMware’s roots began with compute virtualization so when HA was originally released in VMware Virtual Infrastructure 3 (one major revision before it became the vSphere platform known today), the bits licensed and borrowed from Legato Automated Availability Manager (AAM) were designed to protect against marginal but historically documented amounts of x86 hardware failure thereby reducing unplanned downtime and loss of virtualization capacity to a minimum. Basically if an ESX host yields to issues relating to CPU, memory, or network, VMs restart somewhere else in the cluster.
It wasn’t really until vSphere 5.0 that VMware began building in high availability for storage aside from legacy design components such as redundant fabrics, host bus adapters (HBAs), multipath I/O (MPIO), failback policies, and with vSphere 4.0 the pluggable storage architecture (PSA) although this is not to say that any of these design items are irrelevant today – quite the opposite. vSphere 5.0 introduced Permanent Device Loss (PDL) which does a better job of handling unexpected loss of individual storage devices than APD solely did. Subsequent vSphere 5.x revisions made further PDL improvements such as improving support for single LUN:single target arrays in 5.1. In short, the new vSphere HA re-write (Legato served its purpose and is gone now) covers much of the storage gap such that in the event of certain storage related failures, HA will restart virtual machines, vApps, services, and applications somewhere else – again to minimize unplanned downtime. Fundamentally, this works just like HA when a vSphere host tips over, but instead the storage tips over and HA is called to action. Note that HA can’t do much about an entire unfederated array failing – this is more about individual storage/host connectivity. Aside from gross negligence on the part of administrators, I believe the failure scenarios are more likely to resonate with non-uniform stretched or metro cluster designs. However, PDL can also occur in small intra datacenter designs as well.
I won’t go into much more detail about the story that has unfolded with APD and the new features in vSphere 5.x because it has already been documented many times over in some of the links above. Let’s just say the folks starting out new with vSphere 5.1 and 5.5 had it better than myself and many others did dealing with APD and hostd going dark. However, the trade off for them is they are going to have to deal with Software Defined * a lot longer than I will.
Although I mentioned earlier that vSphere HA is extremely simple to configure, I did also mention that was with default options which cover a large majority of the host related failures. Configuring HA to restart VMs automatically and with no user intervention in the event of a PDL condition in theory is just one configuration change for each host in the cluster. Where to configure depends on the version of vSphere host.
vSphere 5.0u1+/5.1: Disk.terminateVMOnPDLDefault = True (/etc/vmware/settings file on each host)
or
vSphere 5.5+: VMkernel.Boot.terminateVMOnPDL = yes (advanced setting on each host, check the box)
One thing about this configuration that had me chasing sense codes in vmkernel logs recently was lack of clarity on the required host reboot. That’s mainly what prompted this article – I normally don’t cover something that has already been covered well by other writers unless there is something I can add, something was missed, or it has caused me personal pain (my blog + SEO = helps ensure I don’t suffer from the same problems twice). In all of the online articles I had read about these configurations, none mentioned a host reboot requirement and it’s not apparent that a host reboot is required until PDL actually happens and automatic VM restart via HA actually does not. The vSphere 5.5 documentation calls it out. Go figure. I’ll admit that sometimes I will refer to a reputable vMcBlog before the product documentation. So let the search engine results show: when configuring VMkernel.Boot.terminateVMOnPDL a host reboot or restart is required. VMware KB 1038578 also calls out that as of vSphere 5.5 you must reboot the host for VMkernel.boot configuration changes to take effect. I’m not a big fan of HA or any configuration being written into VMkernel.boot requiring host or VSAN node performance/capacity outages when a change is made but that is VMware Engineering’s decision and I’m sure there is a relevant reason for it aside from wanting more operational parity with the Windows operating system.
I’ll also reiterate Duncan Epping’s recommendation that if you’re already licensed for HA and have made the design and operational decision to allow HA to restart VMs in the event of a host failure, then the above configuration should be made on all vSphere clustered hosts, whether they are part of a stretched cluster or not to protect against storage related failures. A PDL can be broken down to one host losing all available paths to a LUN. By not making the HA configuration change above, a storage related failure results in user intervention required to recover all of the virtual machines on the host tied to the failed device.
Lastly, it is mentioned in some of the links above but if this is your first reading on the subject, please allow me to point out that the configuration setting above is for Permanent Device Loss (PDL) conditions only. It is not meant to handle an APD event. The reason behind this is that the storage array is required to send a proper sense code to the vSphere host indicating a PDL condition. If the entire array fails or is powered off ungracefully taking down all available paths to storage, it has no chance to send PDL sense codes to vSphere. This would constitute an indefinite All Paths Down or APD condition where vSphere knows storage is unavailable, but is unsure about its return. PDL was designed to answer that question for vSphere, rather than let vSphere go on wondering about it for a long period of time, thus squandering any opportunities to proactively do something about it.
In reality there are a few other configuration settings (again documented well in the links above) which fine tunes HA more precisely. You’ll almost always want to add these as well.
vSphere 5.0u1+: das.maskCleanShutdownEnabled = True (Cluster advanced options) – this is an accompanying configuration that helps vSphere HA distinguish between VMs that were once powered on and should be restarted versus VMs that were already powered off when a PDL occurred therefore these are VMs that don’t need to be and more importantly probably should not be restarted.
vSphere 5.5+: Disk.AutoremoveOnPDL = 0 (advanced setting on each host) – This is a configuration I first read about on Duncan’s blog where he recommends that the value be changed from the default of enabled to disabled so that a device is not automatically removed if it enters a PDL state. Aside from LUN number limits a vSphere host can handle (255), VMware refers to a few cases where the stock configuration of automatically removing a PDL device may be desired although VMware doesn’t really specifically call out each circumstance aside from problems arising from hosts attempting to send I/O to a dead device. There may be more to come on this in the future but for now preventing the removal may save in fabric rescan time down the road if you can afford the LUN number expended. It will also serve as a good visual indicator in the vSphere Client that there is a problematic datastore that needs to be dealt with in case the PDL automation restarts VMs with nobody noticing the event has occurred. If there are templates or powered off VMs that were not evacuated by HA, the broken datastore will visually persist anyway.
That’s the short list of configuration changes to make for HA VM restart. There’s actually a few more here. For instance, fine grained HA handling can be coordinated on a per-VM basis by modifying the advanced virtual machine option disk.terminateVMOnPDLDefault configuration for each VM. Or scsi#:#.terminateVMOnPDL to fine tune HA on a per virtual disk basis for each VM. I’m definitely not recommending touching if the situation does not call for it.
In a stock vSphere configuration with VMkernel.Boot.terminateVMOnPDL = no configured (or unintentionally misconfigured I suppose), the following events occur for an impacted virtual machine:
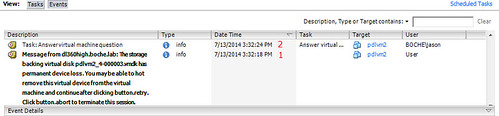
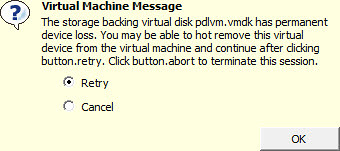
- PDL event occurs, sense codes are received and vSphere correctly identifies the PDL condition on the supporting datastore. A question is raised by vSphere for each impacted virtual machine to Retry I/O or Cancel I/O.
- Stop. Nothing else happens until each of the questions above are answered with administrator intervention. Answering Retry without the PDL datastore coming back online or without hot removing the impacted virtual disk (in most cases the .vmx will be impacted anyway and hot removing disks is next to pointless) sends the VM to hell pretty much. Answering Cancel allows HA to proceed with powering off the VM and restarting it on another host with access to the device which went PDL on the original host.
In a modified vSphere configuration with VMkernel.Boot.terminateVMOnPDL = yes configured, the following events occur for an impacted virtual machine:
- PDL event occurs, sense codes are received and vSphere correctly identifies the PDL condition on the supporting datastore. A question is raised by vSphere for each impacted virtual machine to Retry I/O or Cancel I/O.
- Due to VMkernel.Boot.terminateVMOnPDL = yes vSphere HA automatically and effectively answers Cancel for each impacted VM with a pending question. Again, if the hosts aren’t rebooted after the VMkernel.Boot.terminateVMOnPDL = yes configuration change, this step will mimic the previous scenario essentially resulting in failure to automatically carry out the desired tasks.
- Each VM is powered off.
- Each VM is powered on.
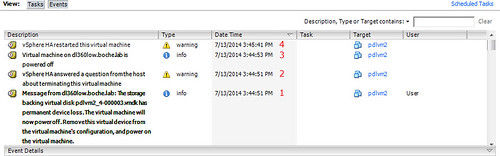
I’ll note in the VM Event examples above, leveraging the power of Snagit I’ve cut out some of the noise about alarms triggering gray and green, resource allocations changing, etc.
For completeness, following is a list of the PDL sense codes vSphere is looking for from the supported storage array:
| SCSI sense code | Description |
H:0x0 D:0x2 P:0x0 Valid sense data: 0x5 0x25 0x0 |
LOGICAL UNIT NOT SUPPORTED |
H:0x0 D:0x2 P:0x0 Valid sense data: 0x4 0x4c 0x0 |
LOGICAL UNIT FAILED SELF-CONFIGURATION |
H:0x0 D:0x2 P:0x0 Valid sense data: 0x4 0x3e 0x3 |
LOGICAL UNIT FAILED SELF-TEST |
H:0x0 D:0x2 P:0x0 Valid sense data: 0x4 0x3e 0x1 |
LOGICAL UNIT FAILURE |
Two isolated examples of PDL taking place seen in /var/log/vmkernel.log:
Example 1:
2014-07-13T20:47:03.398Z cpu13:33486)NMP: nmp_ThrottleLogForDevice:2321: Cmd 0x2a (0x4136803b8b80, 32789) to dev “naa.6000d31000ebf600000000000000006c” on path “vmhba2:C0:T0:L30” Failed: H:0x0 D:0x2 P:0x0 Valid sense data: 0x6 0x3f 0xe. Act:EVAL
2014-07-13T20:47:03.398Z cpu13:33486)ScsiDeviceIO: 2324: Cmd(0x4136803b8b80) 0x2a, CmdSN 0xe1 from world 32789 to dev “naa.6000d31000ebf600000000000000006c” failed H:0x0 D:0x2 P:0x0 Valid sense data: 0x6 0x3f 0xe.
2014-07-13T20:47:03.398Z cpu13:33486)NMP: nmp_ThrottleLogForDevice:2321: Cmd 0x2a (0x413682595b80, 32789) to dev “naa.6000d31000ebf600000000000000007c” on path “vmhba2:C0:T0:L2” Failed: H:0x0 D:0x2 P:0x0 Valid sense data: 0x5 0x25 0x0. Act:FAILOVERExample 2:
2014-07-14T00:43:49.720Z cpu4:32994)ScsiDeviceIO: 2337: Cmd(0x412e82f11380) 0x85, CmdSN 0x33 from world 34316 to dev “naa.600508b1001c6e17d603184d3555bf8d” failed H:0x0 D:0x2 P:0x0 Valid sense data: 0x5 0x20 0x0.
2014-07-14T00:43:49.731Z cpu4:32994)ScsiDeviceIO: 2337: Cmd(0x412e82f11380) 0x4d, CmdSN 0x34 from world 34316 to dev “naa.600508b1001c6e17d603184d3555bf8d” failed H:0x0 D:0x2 P:0x0 Valid sense data: 0x5 0x20 0x0.
2014-07-14T00:43:49.732Z cpu4:32994)ScsiDeviceIO: 2337: Cmd(0x412e82f11380) 0x1a, CmdSN 0x35 from world 34316 to dev “naa.600508b1001c6e17d603184d3555bf8d” failed H:0x0 D:0x2 P:0x0 Valid sense data: 0x5 0x24 0x0.
2014-07-14T00:48:03.398Z cpu10:33484)NMP: nmp_ThrottleLogForDevice:2321: Cmd 0x2a (0x4136823b2dc0, 32789) to dev “naa.60060160f824270012f6aa422e0ae411” on path “vmhba1:C0:T2:L40” Failed: H:0x0 D:0x2 P:0x0 Valid sense data: 0x5 0x25 0x0. Act:FAILOVER
In no particular order, I want to thank Duncan, Paudie, Cormac, Mohammed, Josh, Adam, Niran, and MAN1$H for providing some help on this last week.
By the way, don’t name your virtual machines or datastores PDL. It’s bad karma.
















Hi Joson,
Thanks for the info in article , As you mentioned gone through multiple links to conclude the settings which I should make in my environment.
We have vsphere 6 and IBM SVC, v700 storage.
Could you please suggest me the PDL settings with brief explanation.
Thanks in advance !