A few weeks ago, an associate got me curious about N_Port ID Virtualization (NPIV for short) and what could be done with it in VMware’s current Virtual Infrastructure offerings (VC 2.5u3, ESX 3.5u2). Most of my SAN equipment is a little on the older side so I haven’t had much chance to play with NPIV or investigate its benefits. I decided to head into the lab and kick the tires.
To the best of my knowledge, I thought NPIV was somewhat of a newer technolgoy so the first thing was to inventory my hardware for NPIV capability.
- VMware Virtual Infrastructure 3.5 – check!
- Compaq StorageWorks 4/8 SAN switch – bzzz!
- Preferably 4Gb SFPs but 2Gb should work also – check!
- QLogic 2Gb HBAs – bzzz!
Right off the bat, I’ve got some obstacles to overcome. My SAN switch doesn’t support NPIV in the current firmware version but the fact that it’s a 4GB switch leads me to believe there may be hope in a newer firmware version. The SAN switch needs to support NPIV in any NPIV implementation, VMware or otherwise. The good news is that there’s newer firmware available for the SAN switch. I upgraded the SAN switch firmware and see that I now have NPIV configuration options on my SAN switch. One issue resolved.
To validate whether or not a Brocade switch port supports NPIV, check the Port Admin in the GUI console or run the following command from the switch CLI via telnet:
portcfgshow 1 (where 1 is the switch port number)
If NPIV is disabled, it can easily be enabled via the Port Admin GUI or by using the following command from the switch CLI via telnet:
portCfgNPIVPort 5 1 (where 5 is the port number and 1 is the mode 1=enable, 0=disable)
I don’t have a compatible HBA. That’s a tough one. VMware’s documentation explains “Currently, the following vendors and types of HBA provide [NPIV] support”
- QLogic – any 4GB HBA
- Emulex – 4GB HBAs that have NPIV-compatible firmware
A quick look online at Ebay reveals that 4Gb HBAs are outside of my lab’s budget range (most of the lab budget this year was reallocated for a new deck and sprinkler system for the house – funny how things at home tend to mimic the politics in the office). Fortunately, there’s more than one way to skin a cat. A few emails later and I have a 60 day demo HBA coming from Hewlett Packard (HP’s OEM part number: FC1243 4GB PCI-X 2.0 DC, QLogic’s part number QLA2462).
To validate whether or not your current HBA supports NPIV, open up the ESX console and run the following command:
cat /proc/scsi/qla2300/1 |grep NPIV (where qla2300 is the HBA type and 1 is the HBA number)
For Emulex, it’s going to be something like cat /proc/scsi/lpfc/1 |grep NPIV
Obviously, browse your /proc/scsi/ directory to see what HBAs are in use by ESX.
In addition to the hardware issues, VMware sparsely distributes key NPIV information across several different documents in their library. This is a pet peeve of mine. Nonetheless, these are the VMware documents you need to pay attention to (but like me, you can choose to save the reading until AFTER you run into issues):
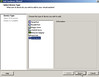
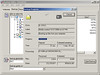
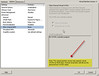
After a few days, the demo HBA from HP arrives. I notice the firmware is from 2005 so I upgrade the firmware to current. I then begin my testing. I connected the fibre beteen the HBA and the SAN switch and powered on the ESX host. Before allowing the ESX host to boot up, I entered the <CTRL + Q> BIOS configuration of the HBA to see if any new NPIV options had been added with the firmware upgrade. None. No mention of NPIV anywhere in the BIOS. I proceeded to allow ESX to boot up. Now that the fibre port is hot, I opened the management interface of the Brocade SAN switch and configured the port for the correct speed and NPIV support (this is configured on a port by port basis). Unfortunately, I’m not seeing that NPIV is in use from the SAN switch point of view. I decide to create a VM and see if I need to enable NPIV inside the VM first. Another roadblock as shown below – the NPIV configuration is essentially all gray’d out and I see a hint at the bottom saying I need RDM storage. I’m not sure why I need RDM. Seems like an odd requirement, but I’ll find out why a little later.
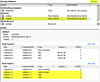
In the lab I have swiSCSI shared storage suitable enough for testing with RDMs. A few mouse clicks later and I have myself a VM with an RDM. I head back to the VM configuration and I’m greeted with the success of being able to add WWNs. Although I could create the WWNs myself by editing the .vmx file by hand, it’s much easier to let ESX assign them for me. ESX generates exactly five WWNs: 1x Node WWN and 4x Port WWNs (the Port WWNs are what you should zone to). It goes without saying that once these WWNs are generated, they should remain static in zoned fabrics (you do zone your fabric don’t you?!).
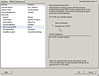
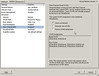
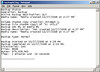
The entries in the .vmx file look like this (really, that’s it):
wwn.node = “25bb000c29000ba5”
wwn.port = “25bb000c29000da5,25bb000c29000ca5,25bb000c29000ea5,25bb000c29000fa5”
wwn.type = “vc”
Two steps forward, one step back. I power cycled the VM a few times and I’m still not seeing any sign of NPIV kicking in on the SAN switch. I should be seeing the virtual WWNs coming online so that I can zone them to something. Referring to the sparse VMware documentation on NPIV, I discovered how VMware’s implementation of NPIV (version 1.0) works and I also learned I was missing a critical hardware component: a SAN. This ties back to my previous questioning of why an RDM is required for NPIV. So quickly, here’s how NPIV works on VMware Virtual Infrastructure when NPIV is enabled (I obtained access to a SAN to work all of this out):
- When the VM is powered on, before the virtual hardware POSTs, it scans the physical HBAs of the ESX host for the RDM mapping to SAN storage. SAN storage connected to HBAs is a hard requirement. If an HBA doesn’t support NPIV, it is skipped in the detection process. If ESX cannot see the zoned RDM LUN through an NPIV aware HBA, the HBA is skipped in the detection process.
- If and when an RDM SAN LUN is discovered through the detection process via an NPIV aware HBA through an NPIV capable SAN switch, fireworks go off and magic happens. One of the four virtual Port WWN s (in the order as they appear in the .vmx file) are assigned to the phsyical HBA and the NPIV virtual Port WWN is activated on the SAN switch.
- ESX will assign a maximum of four NPIV Port WWNs during the detection process. What this means is that if you have four NPIV HBAs connected to four NPIV aware SAN switch ports which are in turn zoned to four SAN LUNs, all four will be NPIV activated. If you have only one NPIV HBA, you’ll only use one of the virtual Port WWNs. If you have six NPIV HBAs, only the first four will be activated with NPIV Port WWNs in the discovery process.
- Zoning and storage presentation. Here’s the catch 22 in this contraption and it’s a big one.
- I can’t get the ESX generated NPIV Port WWNs to activate on the switch until the VM can see RDM SAN LUN storage targets!
- I can’t easily zone RDM SAN storage processors to NPIV Port WWNs until the SAN switch can see the NPIV Port WWNs come online (I use soft zoning by WWN, not hard zoning by physical switch port)!!
- I can’t configure selective storage presentation (easily) on the SAN until the SAN can see the NPIV Port WWNs!!!
- The detection process at VM POST literally takes less than five seconds total to be successful or to fail and one second or less per HBA scan so to coordinate the correct GUI screens in the SAN switch management console, the selective storage presentation SAN console, and the VM console to toggle power state, takes incredible hand/eye coordination and timing. It’s literally lining up all the screens, powering on the VM and hitting the refresh button in each of the SAN management consoles to capture the NPIV Port WWN that briefly comes online during the detection process, then goes away after failing to find an RDM SAN LUN.
- The only way to make this all work easily in my favor is to disable zoning on the SAN switch and disable selective storage presentation on the SAN.
- At any time during the initial detection process or while the VM is already online in operation, should an NPIV hardware or zoning requirement fail to be met for the RDM raw storage on SAN, the VM will fall back to using the Port WWN of the physical HBA it was traversing through it’s NPIV Port WWN assignment.
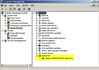
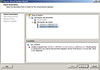
Once I met all of the requirements above and got NPIV working, the result was rather anticlimactic for the amount of effort that was involved. Here’s what NPIV looks like from Port Admin on a Brocade switch (blue is the physical HBA, green in is the NPIV Port WWN that VMware generated):
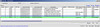 (Zoom in using the Flickr toolbar)
(Zoom in using the Flickr toolbar)
I asked myself the questions “Why would anyone even do this? What are the benefits?”. There aren’t many, at least not right now with this implementation. By far, I think the largest benefit is going to be for the SAN administrator. Maybe a SAN switch port or storage controller is running hot. Without NPIV, we have many VMs communicating with back end SAN storage over a shared HBA which to the SAN administrator appears as a single Port WWN in his/her SAN admin tools. However, with NPIV, the SAN admin tools can now monitor the individual virtualized streams of I/O traffic that tie back to individual VMs. I liken it much to the unique channels in the Citrix ICA protocol that is carried over TCP/IP. Each of those channels can be monitored and in some cases be throttled or given priority. The same concept applies to virtualized channels of VM disk I/O traffic through a physical HBA. Another analogy would be VLANs for disk I/O traffic, but in a very primatave stage.
Another thought for this is to provide a layer of security if we could zone a SAN storage controller solely to an NPIV Port WWN, however, right now this is impossible because as was explained in #5 above, any time the physical HBA is removed from the NPIV visibility chain, NPIV shuts down and falls back to the physical HBA for traffic, and at that point you’ve zoned out your phyiscal HBA and disk I/O traffic would quickly queue and then halt, sending your VM into obvious distress.
A few tips that I’ve personally come up with in this exploration process:
- Don’t remove and then readd NPIV WWNs in the VM once it has all initially been zoned because ESX will assign a completely new set of WWNs.
- If you’ve done the above, you can modify the WWNs by hand in the .vmx file. Remove the VM from inventory first, then modify the .vmx, then readd the VM back to inventory because VirtualCenter (or the VIC) likes to hold on to the generated WWNs if you don’t.
- Adding or removing phsyical HBAs on the host or RDMs on the VM causes the discovery process to mismatch different NPIV Port WWNs with physical HBAs thus throwing off the zoning and causing the whole thing to bomb to the point all NPIV discovery fails.
- If the above happens, you can change the order of the NPIV Port WWN assignment discovery in the .vmx file.
- You can VMotion with NPIV, however, make sure the RDM file is located on the same datastore where the VM configuration file resides. Storage VMotion or VMotion between datastores isn’t allowed with NPIV enabled.
- The location of the RDM metadata (pointer) file can be on SAN or local VMFS storage
- On an HP MSA SAN, the hosts and corresponding Port WWNs can manually be created in the CLI (or temporarily disable SSP to ease the zoning process)
- Removing/adding RDMs can throw off the NPIV Port WWN assignments which in turn throws off zoning
- Discovery order of NPIV Port WWNs is tied to physical HBAs. Adding or removing HBAs throws off the NPIV Port WWN assignments which in turn throws off zoning
Conclusion: This is version 1.0 of VMware NPIV and it functions as such. We need much more flexibility in future versions from all facets: discovery process, better interface for management, editing of the WWNs in the VIC, pinning of WWNs to physcial HBAs, monitoring of NPIV Port WWN disk I/O traffic in VIC performance graphs, guaranteed isolation for security, etc.