Are you thinking about implementing jumbo frames with your IP storage based vSphere infrastructure? Have you asked yourself why or thought about the guaranteed benefits? Various credible sources discuss it (here’s a primer). Some will highlight jumbo frames as a best practice but the majority of what I’ve seen and heard talk about the potential advantages of jumbo frames and what the technology might do to make your infrastructure more efficient. But be careful to not interpret that as an order of magnitude increase in performance for IP based storage. In almost all cases, that’s not what is being conveyed, or at least, that shouldn’t be the intent. Think beyond SPEED NOM NOM NOM. Think efficiency and reduced resource utilization which lends itself to driving down overall latency. There are a few stakeholders when considering jumbo frames. In no particular order:
- The network infrastructure team: They like network standards, best practices, a highly performing and efficient network, and zero down time. They will likely have the most background knowledge and influence when it comes to jumbo frames. Switches and routers have CPUs which will benefit from jumbo frames because processing less frames but more payload overall makes the network device inherently more efficient while using less CPU power and consequently producing less heat. This becomes increasingly important on 10Gb networks.
- The server and desktop teams: They like performance and unlimited network bandwidth provided by magic stuff, dark spirits, and friendly gnomes. These teams also like a postive end user experience. Their platforms, which include hardware, OS, and drivers, must support jumbo frames. Effort required to configure for jumbo frames increases with a rising number of different hardware, OS, and driver combinations. Any systems which don’t support network infrastructure requirements will be a showstopper. Server and desktop network endpoints benefit from jumbo frames much of the same way network infrastructure does: efficiency and less overhead which can lead to slightly measurable amounts of performance improvement. The performance gains more often than not won’t be noticed by the end users except for process that historically take a long amount of time to complete. These teams will generally follow infrastructure best practies as instructed by the network team. In some cases, these teams will embark on an initiative which recommends or requires a change in network design (NIC teaming, jumbo frames, etc.).
- The budget owner: This can be a project sponsor, departmental manager, CIO, or CEO. They control the budget and thus spending. Considerable spend thresholds require business justification. This is where the benefit needs to justify the cost. They are removed from the most of the technical persuasions. Financial impact is what matters. Decisions should align with current and future architectural strategies to minimize costly rip and replace.
- The end users: Not surprisingly, they are interested in application uptime, stability, and performance. They could care less about the underlying technology except for how it impacts them. Reduction in performance or slowness is highly visible. Subtle increases in performance are rarely noticed. End user perception is reality.
The decision to introduce jumbo frames should be carefully thought out and there should be a compelling reason, use case, or business justification which drives the decision. Because of the end to end requirements, implementing jumbo frames can bring with it additional complexity and cost to an existing network infrastructure. Possibly the single best one size fits all reason for a jumbo frames design is a situation where jumbo frames is already a standard in the existing network infrastructure. In this situation, jumbo frames becomes a design constraint or requirement. The evangelistic point to be made is VMware vSphere supports jumbo frames across the board. Short of the previous use case, jumbo frames is a design decision where I think it’s important to weigh cost and benefit. I can’t give you the cost component as it is going to vary quite a bit from environment to environment depending on the existing network design. This writing speaks more to the benefit component. Liberal estimates claim up to 30% performance increase when integrating jumbo frames with IP storage. The numbers I came up with in lab testing are nowhere close to that. In fact, you’ll see a few results where IO performance with jumbo frames actually decreased slightly. Not only do I compare IO with or without jumbo frames, I’m also able to compare two storage protocols with and without jumbo frames which could prove to be an interesting sidebar discussion.
I’ve come across many opinions regarding jumbo frames. Now that I’ve got a managed switch in the lab which supports jumbo frames and VLANs, I wanted to see some real numbers. Although this writing is primarily regarding jumbo frames, by way of the testing regimen, it is in some ways a second edition to a post I created one year ago where I compared IO performance of the EMC Celerra NS-120 among its various protocols. So without further ado, let’s get onto the testing.
Lab test script:
To maintain as much consistency and integrity as possible, the following test criteria was followed:
- One Windows Server 2003 VM with IOMETER was used to drive IO tests.
- A standardized IOMETER script was leveraged from the VMTN Storage Performance Thread which is a collaboration of storage performance results on VMware virtual infrastructure provided by VMTN Community members around the world. The thread starts here, was locked due to length, and continues on in a new thread here. For those unfamiliar with the IOMETER script, it basically goes like this: each run consists of a two minute ramp up followed by five minutes of disk IO pounding. Four different IO patterns are tested independently.
- Two runs of each test were performed to validate consistent results. A third run was performed if the first two were not consistent.
- One ESXi 4.1 host with a single IOMETER VM was used to drive IO tests.
- For the mtu1500 tests, IO tests were isolated to one vSwitch, one vmkernel portgroup, one vmnic, one pNIC (Intel NC360T PCI Express), one Ethernet cable, and one switch port on the host side.
- For the mtu1500 tests, IO tests were isolated to one cge port, one datamover, one Ethernet cable, and one switch port on the Celerra side.
- For the mtu9000 tests, IO tests were isolated to the same vSwitch, a second vmkernel portgroup configured for mtu9000, the same vmnic, the same pNIC (Intel NC360T PCI Express), the same Ethernet cable, and the same switch port on the host side.
- For the mtu9000 tests, IO tests were isolated to a second cge port configured for mtu9000, the same datamover, a second Ethernet cable, and a second switch port on the Celerra side.
- Layer 3 routes to between host and storage were removed to lessen network burden and to isolate storage traffic to the correct interfaces.
- 802.1Q VLANs were used isolate traffic and categorize standard traffic versus jumbo frame traffic.
- RESXTOP was used to validate storage traffic was going through the correct vmknic.
- Microsoft Network Monitor and Wireshark were used to validate frame lengths during testing.
- Activities known to introduce large volumes of network or disk activity were suspended such as backup jobs.
- Dedupe was suspended on all Celerra file systems to eliminate datamover contention.
- All storage tests were performed on thin provisioned virtual disks and datastores.
- The same group of 15 spindles were used for all NFS and iSCSI tests.
- The uncached write mechanism was enabled on the NFS file system for all NFS tests. You can read more about that in the following EMC best practices document VMware ESX Using EMC Celerra Storage Systems
Lab test hardware:
SERVER TYPE: Windows Server 2003 R2 VM on ESXi 4.1
CPU TYPE / NUMBER: 1 vCPU / 512MB RAM (thin provisioned)
HOST TYPE: HP DL385 G2, 24GB RAM; 2x QC AMD Opteron 2356 Barcelona
STORAGE TYPE / DISK NUMBER / RAID LEVEL: EMC Celerra NS-120 / 15x 146GB 15K / 3x RAID5 5×146
SAN TYPE: / HBAs: NFS / swiSCSI / 1Gb datamover ports (sorry, no FCoE)
OTHER: 3Com SuperStack 3 3870 48x1Gb Ethernet switch
Lab test results:
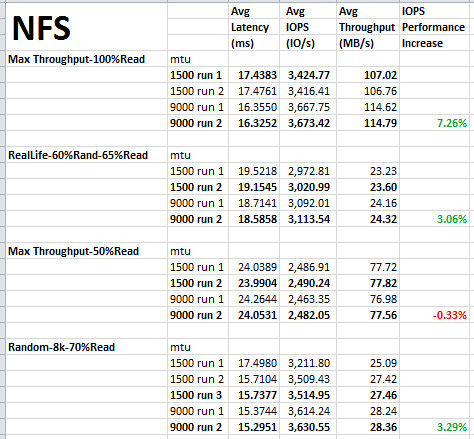
NFS test results. How much better is NFS performance with jumbo frames by IO workload type? The best result seen here is about a 7% performance increase by using jumbo frames, however, 100% read is a rather unrealistic representation of a virtual machine workload. For NFS, I’ll sum it up as a 0-3% IOPS performance improvement by using jumbo frames.
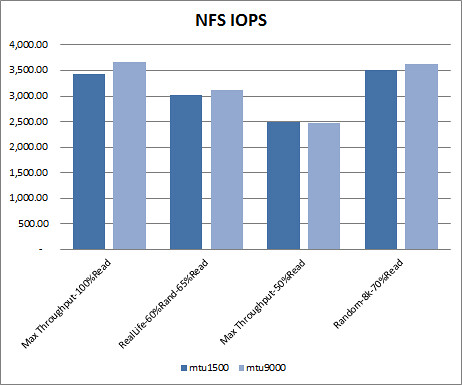
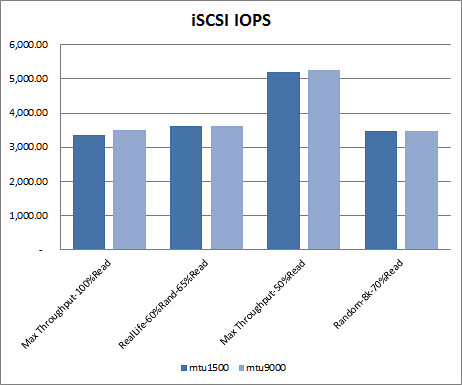
iSCSI test results. How much better is iSCSI performance with jumbo frames by IO workload type? Here we see that iSCSI doesn’t benefit from the move to jumbo frames as much as NFS. In two workload pattern types, performance actually decreased slightly. Discounting the unrealistic 100% read workload as I did above, we’re left with a 1% IOPS performance gain at best by using jumbo frames with iSCSI.

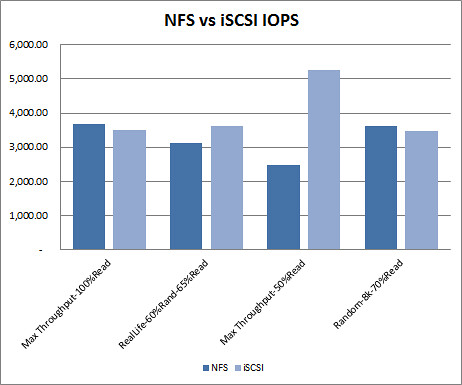
NFS vs iSCSI test results. Taking the best results from each protocol type, how do the protocol types compare by IO workload type? 75% of the best results came from using jumbo frames. The better performing protocol is a 50/50 split depending on the workload pattern. One interesting observation to be made in this comparison is how much better one protocol performs over the other. I’ve heard storage vendors state that the IP protocol debate is a snoozer, they preform roughly the same. I’ll grant that in two of the workload types below, but in the other two, iSCSI pulls a significant performance lead over NFS. Particularly in the Max Throughput-50%Read workload where iSCSI blows NFS away. That said, I’m not outright recommending iSCSI over NFS. If you’re going to take anything away from these comparisons, it should be “it depends”. In this case, it depends on the workload pattern, among a handful of other intrinsic variables. I really like the flexibility in IP based storage and I think it’s hard to go wrong with either NFS or iSCSI.

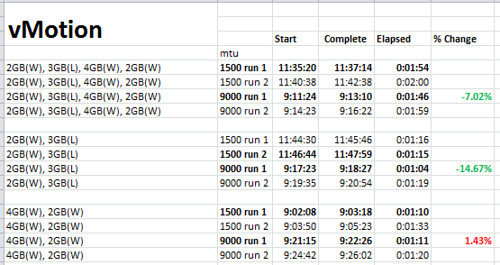
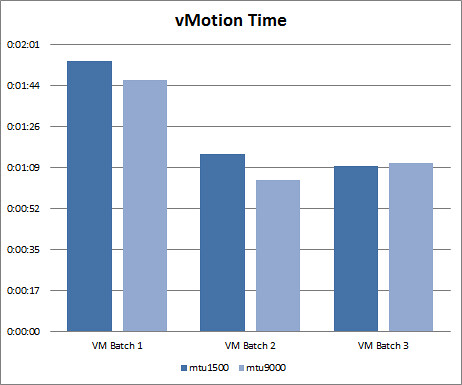
vMotion test results. Up until this point, I’ve looked at the impact of jumbo frames on IP based storage with VMware vSphere. For curiosity sake, I wanted to to address the question “How much better is vMotion performance with jumbo frames enabled?” vMotion utilizes a VMkernel port on ESXi just as IP storage does so the ground work has already been established making this a quick test. I followed roughly the same lab test script outlined above so that the most consistent and reliable results could be produced. This test wasn’t rocket science. I simply grabbed a few different VM workload types (Windows, Linux) with varying sizes of RAM allocated to them (2GB, 3GB, 4GB). I then performed three batches of vMotions of two runs each on non jumbo frames (mtu1500) and jumb frames (mtu9000). Results varied. The first two batches showed that jumbo frames provided a 7-15% reduction in elapsed vMotion time. But then the third and final batch contrasted previous results with data revealing a slight decrease in vMotion efficiency with jumbo frames. I think there’s more variables at play here and this may be a case where more data sampling is needed to form any kind of reliable conclusion. But if you want to go by these numbers, vMotion is quicker on jumbo frames more often than not.
The bottom line:
So what is the bottom line on jumbo frames, at least today? First of all my disclaimer: My tests were performed on an older 3Com network switch. Mileage may vary on newer or different network infrastructure. Unfortunately I did not have access to a 10Gb lab network to perform this same testing. However, I believe my findings are consistent with the majority of what I’ve gathered from the various credible sources. I’m not sold on jumbo frames as a provider of significant performance gains. I wouldn’t break my back implementing the technology without an undisputable business justification. If you want to please the network team and abide by the strategy of an existing jumbo frames enabled network infrastructure, then use jumbo frames with confidence. If you want to be doing everything you possibly can to boost performance from your IP based storage network, use jumbo frames. If you’re betting the business on IP based storage, use jumbo frames. If you need a piece of plausible deniability when IP storage performance hits the fan, use jumbo frames. If you’re looking for the IP based storage performance promise land, jumbo frames doesn’t get you there by itself. If you come across a source telling you otherwise, that jumbo frames is the key or sole ingredient to the Utopia of incomprehendable speeds, challenge the source. Ask to see some real data. If you’re in need of a considerable performance boost of your IP based storage, look beyond jumbo frames. Look at optimizing, balancing, or upgrading your back end disk array. Look at 10Gb. Look at fibre channel. Each of these alternatives are likely to get you better overall performance gains than jumbo frames alone. And of course, consult with your vendor.
















Re: iSCSI performance and frame size
TCP – that’s all that matters
On the Target
What are the NIC and target buffer settings?
(FYI, the Cisco MDS uses max buffer sizes for iSCSI connections on the 1st TCP PDU – since window scaling is detrimental to iSCSI inside a DC environment)
On the Initiator
Sadly, initiators are rather untweakable – but NIC and TCP settings are. Something simple like Reg edit to set TCP acknowledgements to a less aggressive value (same analogy made with big pipe, but long delay)
What matters?
TCP payload loading time on the wire – mainly a function of locality of target and initiator and the TCP tweaking.
TCP acknowledgement frequencies required to support an iSCSI connection. Again, I’m being redundant. It’s just TCP tweaking.
BUT, on the OP’s point – Yes, I’ve been able to Max out GbE and EMC Clariion frame throughput (via MDS targets) using Frame size and MTU of 1500.
Looking toward the future
2 items.
Ethernet will always be in favor.
BUT, consider this. Infiniband in multiplexed. Think of that single pair of wires handling ENET. Infiniband, using all 4 of it’s pairs on a SDR (80 bucks) gets 10 Gb/s with packet distribution across all wires. Analogous to the SCSI LVM connections of old – is it necessary? … Do you want parallel data streams with high throughput in an IP environment? Maybe you do.
Ethernet rule of thumb.
If you have a segmented L2 – use jumbo frames. It can’t hurt (except if if you have flaky firmware)- and it just might hurt not to use them. Don’t put too much thought in to it under these specific circumstances.
SAN, FC, iSCSI admin since 2004 and Infiniband fanboy (since the cards are cheap and it’s multiplexed)