Are you thinking about implementing jumbo frames with your IP storage based vSphere infrastructure? Have you asked yourself why or thought about the guaranteed benefits? Various credible sources discuss it (here’s a primer). Some will highlight jumbo frames as a best practice but the majority of what I’ve seen and heard talk about the potential advantages of jumbo frames and what the technology might do to make your infrastructure more efficient. But be careful to not interpret that as an order of magnitude increase in performance for IP based storage. In almost all cases, that’s not what is being conveyed, or at least, that shouldn’t be the intent. Think beyond SPEED NOM NOM NOM. Think efficiency and reduced resource utilization which lends itself to driving down overall latency. There are a few stakeholders when considering jumbo frames. In no particular order:
- The network infrastructure team: They like network standards, best practices, a highly performing and efficient network, and zero down time. They will likely have the most background knowledge and influence when it comes to jumbo frames. Switches and routers have CPUs which will benefit from jumbo frames because processing less frames but more payload overall makes the network device inherently more efficient while using less CPU power and consequently producing less heat. This becomes increasingly important on 10Gb networks.
- The server and desktop teams: They like performance and unlimited network bandwidth provided by magic stuff, dark spirits, and friendly gnomes. These teams also like a postive end user experience. Their platforms, which include hardware, OS, and drivers, must support jumbo frames. Effort required to configure for jumbo frames increases with a rising number of different hardware, OS, and driver combinations. Any systems which don’t support network infrastructure requirements will be a showstopper. Server and desktop network endpoints benefit from jumbo frames much of the same way network infrastructure does: efficiency and less overhead which can lead to slightly measurable amounts of performance improvement. The performance gains more often than not won’t be noticed by the end users except for process that historically take a long amount of time to complete. These teams will generally follow infrastructure best practies as instructed by the network team. In some cases, these teams will embark on an initiative which recommends or requires a change in network design (NIC teaming, jumbo frames, etc.).
- The budget owner: This can be a project sponsor, departmental manager, CIO, or CEO. They control the budget and thus spending. Considerable spend thresholds require business justification. This is where the benefit needs to justify the cost. They are removed from the most of the technical persuasions. Financial impact is what matters. Decisions should align with current and future architectural strategies to minimize costly rip and replace.
- The end users: Not surprisingly, they are interested in application uptime, stability, and performance. They could care less about the underlying technology except for how it impacts them. Reduction in performance or slowness is highly visible. Subtle increases in performance are rarely noticed. End user perception is reality.
The decision to introduce jumbo frames should be carefully thought out and there should be a compelling reason, use case, or business justification which drives the decision. Because of the end to end requirements, implementing jumbo frames can bring with it additional complexity and cost to an existing network infrastructure. Possibly the single best one size fits all reason for a jumbo frames design is a situation where jumbo frames is already a standard in the existing network infrastructure. In this situation, jumbo frames becomes a design constraint or requirement. The evangelistic point to be made is VMware vSphere supports jumbo frames across the board. Short of the previous use case, jumbo frames is a design decision where I think it’s important to weigh cost and benefit. I can’t give you the cost component as it is going to vary quite a bit from environment to environment depending on the existing network design. This writing speaks more to the benefit component. Liberal estimates claim up to 30% performance increase when integrating jumbo frames with IP storage. The numbers I came up with in lab testing are nowhere close to that. In fact, you’ll see a few results where IO performance with jumbo frames actually decreased slightly. Not only do I compare IO with or without jumbo frames, I’m also able to compare two storage protocols with and without jumbo frames which could prove to be an interesting sidebar discussion.
I’ve come across many opinions regarding jumbo frames. Now that I’ve got a managed switch in the lab which supports jumbo frames and VLANs, I wanted to see some real numbers. Although this writing is primarily regarding jumbo frames, by way of the testing regimen, it is in some ways a second edition to a post I created one year ago where I compared IO performance of the EMC Celerra NS-120 among its various protocols. So without further ado, let’s get onto the testing.
Lab test script:
To maintain as much consistency and integrity as possible, the following test criteria was followed:
- One Windows Server 2003 VM with IOMETER was used to drive IO tests.
- A standardized IOMETER script was leveraged from the VMTN Storage Performance Thread which is a collaboration of storage performance results on VMware virtual infrastructure provided by VMTN Community members around the world. The thread starts here, was locked due to length, and continues on in a new thread here. For those unfamiliar with the IOMETER script, it basically goes like this: each run consists of a two minute ramp up followed by five minutes of disk IO pounding. Four different IO patterns are tested independently.
- Two runs of each test were performed to validate consistent results. A third run was performed if the first two were not consistent.
- One ESXi 4.1 host with a single IOMETER VM was used to drive IO tests.
- For the mtu1500 tests, IO tests were isolated to one vSwitch, one vmkernel portgroup, one vmnic, one pNIC (Intel NC360T PCI Express), one Ethernet cable, and one switch port on the host side.
- For the mtu1500 tests, IO tests were isolated to one cge port, one datamover, one Ethernet cable, and one switch port on the Celerra side.
- For the mtu9000 tests, IO tests were isolated to the same vSwitch, a second vmkernel portgroup configured for mtu9000, the same vmnic, the same pNIC (Intel NC360T PCI Express), the same Ethernet cable, and the same switch port on the host side.
- For the mtu9000 tests, IO tests were isolated to a second cge port configured for mtu9000, the same datamover, a second Ethernet cable, and a second switch port on the Celerra side.
- Layer 3 routes to between host and storage were removed to lessen network burden and to isolate storage traffic to the correct interfaces.
- 802.1Q VLANs were used isolate traffic and categorize standard traffic versus jumbo frame traffic.
- RESXTOP was used to validate storage traffic was going through the correct vmknic.
- Microsoft Network Monitor and Wireshark were used to validate frame lengths during testing.
- Activities known to introduce large volumes of network or disk activity were suspended such as backup jobs.
- Dedupe was suspended on all Celerra file systems to eliminate datamover contention.
- All storage tests were performed on thin provisioned virtual disks and datastores.
- The same group of 15 spindles were used for all NFS and iSCSI tests.
- The uncached write mechanism was enabled on the NFS file system for all NFS tests. You can read more about that in the following EMC best practices document VMware ESX Using EMC Celerra Storage Systems
Lab test hardware:
SERVER TYPE: Windows Server 2003 R2 VM on ESXi 4.1
CPU TYPE / NUMBER: 1 vCPU / 512MB RAM (thin provisioned)
HOST TYPE: HP DL385 G2, 24GB RAM; 2x QC AMD Opteron 2356 Barcelona
STORAGE TYPE / DISK NUMBER / RAID LEVEL: EMC Celerra NS-120 / 15x 146GB 15K / 3x RAID5 5×146
SAN TYPE: / HBAs: NFS / swiSCSI / 1Gb datamover ports (sorry, no FCoE)
OTHER: 3Com SuperStack 3 3870 48x1Gb Ethernet switch
Lab test results:
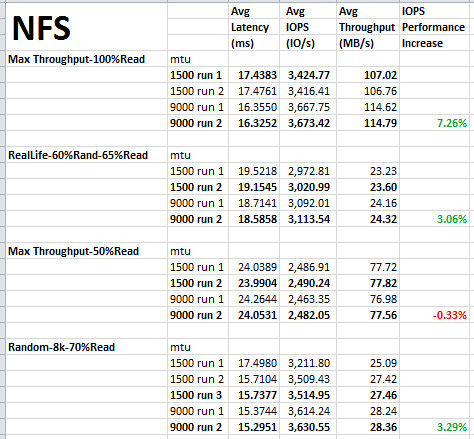
NFS test results. How much better is NFS performance with jumbo frames by IO workload type? The best result seen here is about a 7% performance increase by using jumbo frames, however, 100% read is a rather unrealistic representation of a virtual machine workload. For NFS, I’ll sum it up as a 0-3% IOPS performance improvement by using jumbo frames.
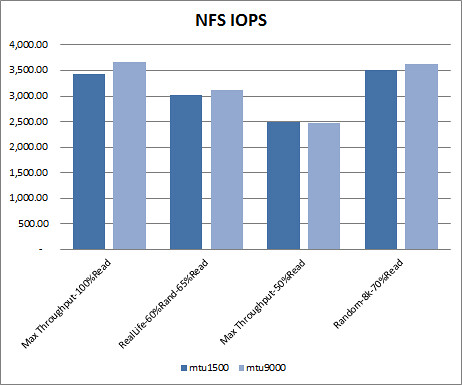
iSCSI test results. How much better is iSCSI performance with jumbo frames by IO workload type? Here we see that iSCSI doesn’t benefit from the move to jumbo frames as much as NFS. In two workload pattern types, performance actually decreased slightly. Discounting the unrealistic 100% read workload as I did above, we’re left with a 1% IOPS performance gain at best by using jumbo frames with iSCSI.

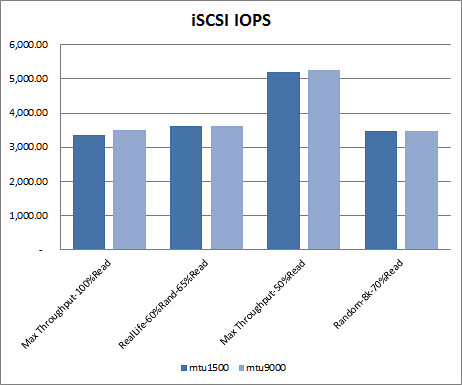
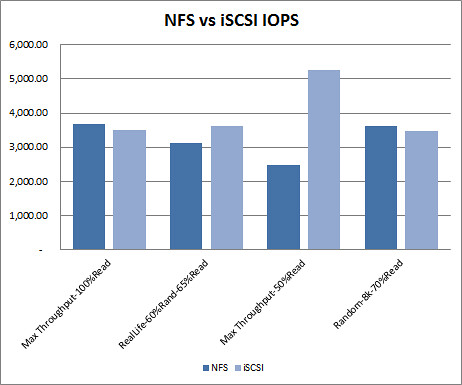
NFS vs iSCSI test results. Taking the best results from each protocol type, how do the protocol types compare by IO workload type? 75% of the best results came from using jumbo frames. The better performing protocol is a 50/50 split depending on the workload pattern. One interesting observation to be made in this comparison is how much better one protocol performs over the other. I’ve heard storage vendors state that the IP protocol debate is a snoozer, they preform roughly the same. I’ll grant that in two of the workload types below, but in the other two, iSCSI pulls a significant performance lead over NFS. Particularly in the Max Throughput-50%Read workload where iSCSI blows NFS away. That said, I’m not outright recommending iSCSI over NFS. If you’re going to take anything away from these comparisons, it should be “it depends”. In this case, it depends on the workload pattern, among a handful of other intrinsic variables. I really like the flexibility in IP based storage and I think it’s hard to go wrong with either NFS or iSCSI.

vMotion test results. Up until this point, I’ve looked at the impact of jumbo frames on IP based storage with VMware vSphere. For curiosity sake, I wanted to to address the question “How much better is vMotion performance with jumbo frames enabled?” vMotion utilizes a VMkernel port on ESXi just as IP storage does so the ground work has already been established making this a quick test. I followed roughly the same lab test script outlined above so that the most consistent and reliable results could be produced. This test wasn’t rocket science. I simply grabbed a few different VM workload types (Windows, Linux) with varying sizes of RAM allocated to them (2GB, 3GB, 4GB). I then performed three batches of vMotions of two runs each on non jumbo frames (mtu1500) and jumb frames (mtu9000). Results varied. The first two batches showed that jumbo frames provided a 7-15% reduction in elapsed vMotion time. But then the third and final batch contrasted previous results with data revealing a slight decrease in vMotion efficiency with jumbo frames. I think there’s more variables at play here and this may be a case where more data sampling is needed to form any kind of reliable conclusion. But if you want to go by these numbers, vMotion is quicker on jumbo frames more often than not.
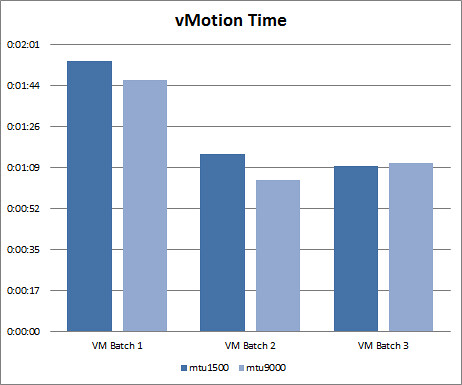
The bottom line:
So what is the bottom line on jumbo frames, at least today? First of all my disclaimer: My tests were performed on an older 3Com network switch. Mileage may vary on newer or different network infrastructure. Unfortunately I did not have access to a 10Gb lab network to perform this same testing. However, I believe my findings are consistent with the majority of what I’ve gathered from the various credible sources. I’m not sold on jumbo frames as a provider of significant performance gains. I wouldn’t break my back implementing the technology without an undisputable business justification. If you want to please the network team and abide by the strategy of an existing jumbo frames enabled network infrastructure, then use jumbo frames with confidence. If you want to be doing everything you possibly can to boost performance from your IP based storage network, use jumbo frames. If you’re betting the business on IP based storage, use jumbo frames. If you need a piece of plausible deniability when IP storage performance hits the fan, use jumbo frames. If you’re looking for the IP based storage performance promise land, jumbo frames doesn’t get you there by itself. If you come across a source telling you otherwise, that jumbo frames is the key or sole ingredient to the Utopia of incomprehendable speeds, challenge the source. Ask to see some real data. If you’re in need of a considerable performance boost of your IP based storage, look beyond jumbo frames. Look at optimizing, balancing, or upgrading your back end disk array. Look at 10Gb. Look at fibre channel. Each of these alternatives are likely to get you better overall performance gains than jumbo frames alone. And of course, consult with your vendor.
















Disclaimer – EMCer here…
Thanks Jason, great through work – and I totally agree. While some swear by Jumbo Frames, I’ve found the upside (minimal) to be outweighed by the downside (someone makes a mistake somewhere, and packet fragmentation errors cause a nightmare).
Thanks for all the statistics Jason.
There is one thing that is not often taken into account – correct if I am wrong but this is the case here as well.
The perspective of the physcial Switch.
What are the differences between the different MTU’s on the Switch Load?
(Disclaimer: I work for EMC.)
Jason, thanks for the great work on these results. I agree with your conclusions—unless there is a compelling business reason, the general rule of “Keep it as simple as possible but no simpler” applies.
disclaimer…BlueArc here
You need to test a bigger environment with a beefier box than an NS120 with 15 drives to see the benefit of jumbo frames. Unless your LAN ports are part of the bottleneck, jumbo frames won’t improve your throughput or IOPS.
Although in an offhand way, this agrees with your point, I think. Jumbo frames don’t automatically mean better performance. If the customer isn’t deploying a system that can take advantage of jumbo frames, the complexity of it may not make sense.
Thank’s for this demo ! Really amazing, as everyone tell jumbo or giant frames are necessary for vMotion ?
I would like to have the same test on my CISCO Catalyst 2960G …
Regards,
Vincent RABAH
I agree that it won’t necessarily be 30% improvement. For 10g it will make a big difference. I find also it makes quite a difference on the type of switch used in terms of port cache and the like. Same goes for the type of NICs and whether the host OS uses tx/rx offload. I would be interested to see the perf difference on something like 2008R2 or RHEL-6 where their IO workloads have been tweaked massively to improve these scenarios. EG RHEL-5/6 and Solaris we see much bigger perf improvements with Jumbo with nfs/iSCSI than we do with some older OS. Same goes with switches c6509-E with 6748+DFC vs older 6509 with SUP2 + older cards don’t see the increase.
Dimitris from NetApp here…
I’d have tested the CPU impact on both host and array with jumbo if I were you. For instance, if jumbo, even on a smaller box, offers a significantly less CPU hit, then it might be worth it.
In general, I’d only go out of my way doing jumbo with 10G environments and boxes beefier than an NS120.
D
Thanks for the article!
Quick question…I saw you changed the port groups to 9000 mtu, but I didn’t see that you changed the vSwitch to 9000? Can you confirm?
Wow this was a pretty neat read. You put in a lot of work, and it paid off for me ;). I’ve never delt with any ip based storage outside of a crash-and-burn lab. I’ve been lucky enough to always have fibre channel for production workload. However, I do run across many people that swear jumbo frames is some magic bullet. Obviously not.
@Dustin
When performing jumbo frames testing, mtu9000 was configured both on the vmknic and the vSwitch which owned the portgroup which the vmknic used. I also verified frames on the wire were the appropriate size based on the test being conducted using 2 different sniffers.
@Dimitris
During the first few tests, I was watching CPU time on the ESXi host. The CPU utilization delta between tests on the ESXi host seemed inconsequential and so I stopped monitoring host CPU. That said, there are a lot of ESX/ESXi hosts deployed globally without using jumbo frames. Any CPU savings which jumbo frames provide could be beneficial to the host but the question that should be weighed is would the host CPU savings be impactful? To claim a host should be configured for jumbo frames from a CPU standpoint is saying in a round about way that available CPU on the host is a constraint that is limiting potential. For CPU constrained environments, this may be true, but the vast majority of the environments I’ve looked at, memory is the limiting resource and memory population in hosts isn’t proportionate to CPU cores, typically because of the cost of high memory density on commodity hardware, especially blades. So in most common situations, it’s like putting lipstick on a pig from a host benefit standpoint. That said, I didn’t monitor CPU utilization on the switch (I’m not sure if there is a method to do so on this model) or the Celerra’s datamover. I can easily run some tests again and watch datamover CPU on the Celerra if feel jumbo frames are a game changer there. It might a lesson in futility though as a few EMCers have already chimed in with a nod of agreement on the test that was conducted.
@Julie
Thank you for the comment. I hear what you’re saying, but I don’t necessarily agree with all of it from the data I gathered. I think the Celerra with 15 spindles has enough horsepower to fill a 1Gb pipe. During the Max Throughput 100% read tests, RESXTOP on the host was reporting very near 100% utilization on the vmknic. Essentially 950-989Mbps on a 1Gb link. VMware ESXi also has no problem filling a 1Gb pipe effectively. I witnessed this in both the previously mentioned storage tests as well as with the vMotion testing.
@All
Thank you for the comments. As usual they are always welcomed and I value them. I’d love to be able to perform more testing on other equipment but listed is what I have to work with. Even though the equipment is older, I think the classic use of a control group and experimental group produced data which has relevance and merit. If you’d like to pony up a Nexus 5k or Blade System with 10Gb, I’ll be happy to provide you with my shipping address 🙂
164MB/S on 1 Gbit link ? Thats more then the link can actually do?
Jason,
Great article and congrats on passing your VCAP4-DCD and becoming VCDX4, that’s pretty awesome. Great info on the IO comparison, I was wondering about CPU load reductions across the infrastructure as well, but after finally reading all the comments, I see you guys hashed it out already 🙂
Congrats again and I’m confident that IF someone should pony up all that gear for 10GbE testing, you have the circuits in place to power it all, right? 😛
Thanks,
-David
Good article Jason! One question. What was the average packet sizes on the 1500MTU and 9000MTUs?
Fantastic article! I so rarely see content with sufficient details to draw any meaningful conclusions or inspires such confidence in the author.
My biggest curiosity was already touched on by another commenter: I would love to see the results for a Windows 2008 or more modern Linux/Unix OS guest VM since they have made significant performance improvements in their network stack.
A coworker and I have been working on a ZFS based storage box (not as fancy/expensive as your Celerra) and we have a 120GB SSD read cache and ~12GB of system RAM that ZFS uses as a write cache. So far we have seen fantastic IOMeter IOPS results and I would like to use the same test scripts that you mention. I think a setup like ours with a lot of cache might be better suited to isolating the performance delta between the 1500/9000 MTU and reduce the dependency/impact of the actual array’s spinning disk performance. Hopefully we can get it working and submit some of our data… I will post back here if/when we get it working!
Jason,
Great post on Jumbo Frames. I have to agree with the majority here, I try to keep things as simple as they can be. There are times when not everyone on your team has the skill to manage this type of customization and it can cause a headache down the road. Great stats, as always very thorough.
-Greg
Jason,
I double everyone else, a great post with wonderful details, wish more posts were like this 🙂
Looking at jumbo-frames and its’ subsequent impact on protocol stack, this is exactly what I expected to see. Jumbo frames do (directly) nothing to iSCSI performance, as iSCSI is constrained by the performance of the TCP layer, where the 64k window size will slow you down (i.e. iSCSI should see next to no benefit). The only thing that jumbo frames changes is how many socket send() calls one has to issue to shovel the same amount of data out.
An example of sending max tcp send window worth of data (64kB) – means 65536/1460 = 45 send() calls without jumbo frames, and the same amount of ack packets to handle (in worst case).
Using jumbo frames, the same data should go out in 8 send() calls (and less acks) – thus less CPU consumption on both sides.
In either case – whether jubo frames or not, the cpu is usually able to fill the lan bandwidth – unless the sender has to stop because of send window consumed and no ack from the peer.
With NFS one would expect different results, but depending on whether it is configured to run over tcp or udp. With tcp it will face the same windowing issue than any other tcp user; but with UDP it would not be constrained by level4 protocol but something else – likely the NFS itself since the responsibility of guaranteed data transfer is moved from the transport layer(4) to the application layer(7).
It was also great to see the comparison of NFS and iSCSI, yet it begs the question in my mind whether NFS used udp or tcp in this test. I am used to seeing it over udp (which is the default afaik), just wondering what might been the case here.
Keep up the good work!
-Eero
Hi Jason,
Very interesting post… I would expect to see some improvement in performance, looks like the improvement is negligible from your results. I’m wondering if another test (outside of a VM environment) would yield similar results or if your results are only applicable to a VM environment.
Like Tom I’m interested in what the average frame size was (if you still have the packet traces around).
Thanks for sharing!
Hello Jason
Thanks for the test, I will show it to all who say the jumbo frame are a must have technic. I tell people that jumbo frames only effect some very few implementation. I see jumbo frames as more trouble then benefit for the moment and the benefit needs to be evaluated before implement jumbo frames, as you did.
It’s so much other stuff happen on top of the ethernet frame the will restrict the performance for most TCP/UDP flows. In other words, there are very few flows that will come close to 9000 (or even 1500) byte in average packet size, and even fewer who gain from implementing jumbo frames.
I try to tell people to use the TCP windows scaling (>64Kbyte) and try to get the *application* to really use that scaling. I think that is much more important then jumbo frames in most cases.
Of course there are some exception to my point, and yes, in such case jumbo frames makes a difference. But before I implement jumbo frames I would do as you did Jason, test it.
Best Regard
– Per Håkansson
I’ve been running iSCSI (openfiler) for better than a year on a Dell 2850. Originally I was running the 32bit version but upgraded to the 64bit version. I found that the cpu and memory load on the server is much less when using the 64bit version. I haven’t done any tests to see if the version change impacted the throughput.
Hi Jason, Testing I’ve done on 10G links shows massive improvement just by using Jumbo Frames. But granted it probably won’t show much improvement on a 1Gb/s network as most everything can saturate it. vMotion for example will top out at 800 – 900MB/s with 1500 MTU and will easily exceed 1250MB/s with 9000MTU on ESXi 5 single NIC tests. With dual 10G test I topped out at around 1600MB/s because I was CPU constrained on my servers. Also the theoretical throughput limit for 1Gb/s is 125MB/s, which you should be able to easily hit with Jumbo turned on when doing vMotion.
Hello Jason,
Someone pointed me to this article and after reading it i was wondering what MTU size was set on the 3COM switch.
Thanks!
@JBosman: IIRC there is only 1 setting on the 3COM switch I tested with – Jumbo Frames enabled or disabled. MTU was configured for 9000 on all endpoint interfaces during the tests.
Great testing and very detailed. Perhaps you can run the test with the IO Analyzer that vmware provided in a fling earlier this year. There are roughly 50 different IO workloads you can simulate with a canned centos vm host.
Good to have data to show if it makes a difference or not. I always wondered about the utopia that is Jumbo Frames, but sounds like KISS applies again. Unless there is a requirement to get every bit of performance that you can, otherwise its a nominal change.
My testing on 10G shows a much bigger difference between Jumbo and non-Jumbo. It’s still definitely worth considering.
Also… depending on the type of switch (the type and class of the switch really matters a lot here) you can gain some performance for iscsi, both 1500 and 9000 mtu, if you are able to put your iscsi traffic into the priority queue/low latency queue on the switches. you will lower your latency by doing this.
typically this is used for voice traffic, but if you’ve correctly separated your voice and storage traffic, this shouldn’t be an issue.
Any idea if testing 4k as an MTU size would make any difference? I’ve read some materials that indicate 4k performed better than 1500 and 9000 in some cases.
I’d like to rehash this post. Especially now since vSphere storage vmotions automagically across L2 networks.
We have 2 management nics. One for Management Traffic only(vmk0), and one for vMotion traffic only(vmk1).
I would like to know 2 things.
1) Since management traffic runs over SSL. Does vmk0 management traffic fragment when MTU is set at 1500, should I set it at 1600
2) Does Storage vMotion traffic use Jumbo Frames, and if so, should I set my vmk1 nic to 9000MTU
Frankly, I was surprised to see the results in this post and decided to verify it.
My tests also showed 0-3% of performance enhancement using Jumbo Frames.
Here is what I did:
vmk1: 9000 MTU
vSwitch: 9000 MTU
Cisco 3750 : 9000 MTU
NetApp Filer: 9000 MTU.
VM size: 10.46 GB MTU 9000 MTU 1500 Difference
vMotion (F1 to F4) 6 mins 29 secs 6 mins 35 secs
vMotion (F1 to F4) 6 mins 33 secs 6 mins 35 secs
vMotion (F4 to F1) 6 mins 31 secs 6 mins 33 secs
vMotion (F4 to F1) 6 mins 31 secs 6 mins 32 secs
Average (secs) 391 393.75 1%
Offline Migration (F1 to F4) 6 mins 27 secs 6 mins 33 secs
Offline Migration (F1 to F4) 6 mins 29 secs 6 mins 34 secs
Offline Migration (F4 to F1) 6 mins 28 secs 6 mins 30 secs
Offline Migration (F4 to F1) 6 mins 27 secs 6 mins 33 secs
Average (secs) 387.25 392.5 1%
Cloning (F1 to F4) 6 mins 31 secs 6 mins 31 secs 0%
DataSize: 102 MB (in Seconds) (in Seconds)
Copy-Paste 1st (after reboot) 13 14
Copy-Paste 1st (after reboot) 13 13
Copy-Paste 2nd (after 1st copy) 4 4
Copy-Paste 2nd (after 1st copy) 4 4
Average 8.5 8.75 3%
VM Boot time 13 13 0%
NOTE:
F1 = NetApp Filer 1
F4 = NetApp Filer 4
Thanks Jason for the extensive research.
I read your article because I was challenged recently on the reason I failed to implement jumbo frames on a 2-way replicated vmware solution running LH P4000 VSA’s.
I really thought it was a huge issue. Thank goodness it is not.
I feel personally I would not implement jumbo frames unless I was dealing with a 10Gig Core.
Thanks so much for your article.
Remember when virtualizing that it’s not just about increase in network performance but also a decrease in CPU utilization that can be a benefit of Jumbo Frames. Depending on your environment this may have a more important benefit than the 1% difference in performance. With 10G infrastructure my testing found more like a 10% difference, which is worth while gaining, and this magnifies the more NIC’s you have on your hosts. But I wouldn’t normally bother with Jumbo Frames unless on 10G networking or higher as the benefit is not there for the additional effort.
You aren’t going to get much of a break with sub 5ms latency between hosts. Where you get your biggest break is in high latency, long distance connections with a fat pipe. For example, a GigE circuit from LA to Atlanta would get much more advantage with jumbo frames on a point to point link capable of them.
You also have to understand that some of the benefit comes in other ways. If your CPU is calculating packet checksums, you have 6x fewer of them to calculate. In the network core, switch resources are by packet, not per bit. Switching and routing loads decrease with jumbo frames. But, as I mentioned above, you find your biggest performance boost over distance. If you have a dark fiber link between data centers or maybe someone can provision you with a 9000 byte or 7500 byte clean point to point between locations, it will make a huge difference. One single ACK handles as much traffic as 6 acks. TCP is dependent on latency for speed. If you can send more data per RTT period, you win.