In the past couple of weeks I have spent some time with VMware vCloud Director 1.5. The experience yielded three blog articles Collecting diagnostic information for VMware vCloud Director, Expanding vCloud Director Transfer Server Storage and now this one.
In this round, the vCD cell stopped working properly (single cell server environment). I could log into the vCD provider and organization portals but the deployment of vApps would run for an abnormally long time and then fail after 20 minutes with one of the resulting failure messages being Failed to receive status for task.
Doing some digging in the environment I found a few problems.
Problem #1: None of the cells have a vCenter proxy service running on the cell server.

Problem #2: Performing a Reconnect on the vCenter Server object resulted in Error performing operation and Unable to find the cell running this listener.

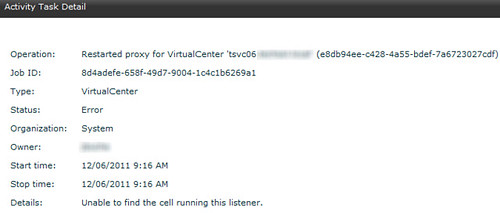
I search the Community Forums, talked with Chris Colotti (read his blog) for a bit, and then opened an SR with VMware support. VMware sent me a procedure along with a script to run on the Microsoft SQL Server:
- BACKUP the entire SQL Database.
- Stop all cells. (service vmware-vcd stop)
- Run the attached reset_qrtz_tables_sql_database.sql
— shutdown all cells before executing
delete from qrtz_scheduler_state
delete from qrtz_fired_triggers
delete from qrtz_paused_trigger_grps
delete from qrtz_calendars
delete from qrtz_trigger_listeners
delete from qrtz_blob_triggers
delete from qrtz_cron_triggers
delete from qrtz_simple_triggers
delete from qrtz_triggers
delete from qrtz_job_listeners
delete from qrtz_job_details
go - Start one cell and verify if issue is resolved. (service vmware-vcd start)
- Start the remaining cells.
Before running the script I knew I had to make a few modifications to select the vCloud database first.
When running the script, it failed due to case sensitivity with respect to the table names. Upon installation, vCD creates all tables with upper case names. When the MS SQL Server database was first created by yours truly, case sensitivity, along with accent sensitivity, were enabled with COLLATE Latin1_General_CS_AS which comes straight from page 17 of the vCloud Director Installation and Configuration Guide.
After fixing the script, it looked like this:
USE [vcloud]
GO
— shutdown all cells before executing
delete from QRTZ_SCHEDULER_STATE
delete from QRTZ_FIRED_TRIGGERS
delete from QRTZ_PAUSED_TRIGGER_GRPS
delete from QRTZ_CALENDARS
delete from QRTZ_TRIGGER_LISTENERS
delete from QRTZ_BLOB_TRIGGERS
delete from QRTZ_CRON_TRIGGERS
delete from QRTZ_SIMPLE_TRIGGERS
delete from QRTZ_TRIGGERS
delete from QRTZ_JOB_LISTENERS
delete from QRTZ_JOB_DETAILS
go
The script ran successfully wiping out all rows in each of the named tables. A little sidebar discussion here.. I talked with @sqlchicken (Jorge Segarra, read his blog here) about the delete from statements in the script. It is sometimes a best practice to use the truncate table statement instead so that the transaction logs are bypassed instead of using the delete from statement which is more resource intensive due to the row by row deletion method and the rows being recorded in the transaction logs. Thank you for that insight Jorge! More on MS SQL Delete vs Truncate here. Jorge was also kind enough to provide a link on the subject matter but credentials will be required to view the content.
I was now able to restart the vCD cell and my problems were gone. Everything was working again. All errors have vanished. I thanked the VMware support staff and then tried to gain a little bit more information about how the problem was resolved by deleting table rows and what exactly are the qrtz tables? I had looked at the table rows myself before they were deleted and the information in there didn’t make a lot of sense to me (but that doesn’t necessarily classify it as transient data). This is what he had to say:
These [vCenter Proxy Service] issues are usually caused by a disconnect from the database, causing the tables to become stale. vCD constantly needs the ability to write to the database and when it cannot, the cell ends up in a state that is similar to the one that you have seen.
The qrtz tables contain information that controls the coordinator service, and lets it know when the coordinator to be dropped and restarted, for cell to cell fail over to another cell in multi cell enviroment.
When the tables are purged it forces the cell on start up to recheck its status and start the coordinator service. In your situation the cell, due to corrupt records in the table was not allowing this to happen.
So by clearing them forced the cell to recheck and to restart the coordinator.
Good information to know going forward. I’m going to keep this in my back pocket. Or on my blog as it were. Have a great weekend!
















Nice work Jason. Do we know the root cause yet of what put the DB in issue in the first place? I did not see that here with the fix? DO we even know why the proxy got hung up to begin with?
Chris, great question. VMware support wasn’t able to perform RCA. The closest he could get was to provide a common scenario which can lead to this issue: a disconnection from the database. This particular environment exists in the lab where infrastructure tends to become unavailable unexpectedly. There was also a vCenter uninstall/reinstall (which provided vCD resources) for the purposes of migrating the vCenter database to an alternate SQL Server. I don’t know if the vCD service was stopped during this process or not. These events tie into the possible explanation.
Thanks for the shoutout! But just to clarify, even in Simple Mode, your transaction log can still grow large as deletes are still logged. Check out this pretty good article that dives deeper into the topic.
http://www.sqlservercentral.com/articles/delete/61387/
Thanks Jason. I’m hoping this occurred in a test environment. Makes me wonder if vCD is the right direction to go for a hosting data center like we are building.
It was a test environment but I could see how an issue like this would be cause for concern. It is assumed the back end database was unavailable at some point and since vCD is reliable on said database, that is how the issue came about. The key take away here is high availability for the infrastructure components. Nothing new in our world but the impact in this situation took some time in figuring out how to resolve.
Thank you Jason!! This worked wonderfully for me. I was about to rebuild the entire environment. The only thing I did prior to it failing was update the SSL certificates from self-signed to our local rootCA store.
After that, I couldn’t import from vCenter and had similar issues that Jason mentions in his article. After digging, I also found the “proxy service not running” error message.
So, I did a search, found this, and now I’m back in business. Grateful to you Jason, Chris and Jorge!
Bravo!
-Greg
Always glad to help Greg. Rebuilding the vCD environement is not a pretty option!
Nice! Worked fine.
I’ll see to it KB 1035506 is updated to address this. Thanks Jason!
Thanks so much Rick!
Hit this issue today and this post resolved the it…cheers Jason. I re-posted the fix with credits on my blog here https://lifeofbrianoc.wordpress.com/2015/07/18/vcloud-director-error-none-of-the-cells-have-a-vcenter-proxy-service-running/
Hope thats ok!
Thanks again!
Excellent – glad you got the issue resolved! I love finding this stuff!