Speaking for myself, it’s hard to believe that just a little over 2 years ago in October 2010, many were rejoicing the GA release of vSphere 4.1 and its awesome new features and added scalability. It seems so long ago. The following February 2011, Update 1 for vSphere 4.1 was launched and I celebrated my one year anniversary as a VCDX certificate holder. Now two years later, 5.0 and 5.1 have both seen the light of day along with a flurry of other products and acquisitions rounding out and shaping what is now the vCloud Suite. Today I’m as much involved with vSphere as I think I ever have been. Not so much in the operational role I had in the past, but rather a stronger focus on storage integration and meeting with Dell Compellent/VMware customers on a regular basis.
I began this article with vSphere 4.1 for a purpose. vSphere 4.1 shipped with a new Enterprise Plus feature named vStorage APIs for Array Integration or VAAI for short (pronounced ‘vee double-ehh eye’ to best avoid twist of the tongue). These APIs offered three different hardware offload mechanisms for block storage enabling the vSphere hypervisor to push some of the storage related heavy lifting to a SAN which supported the APIs. One of the primitives in particular lies at the root of this topic and a technical marketing urban myth that I have seen perpetuated off and on since the initial launch of VAAI. I still see it pop up from time to time through present day.
One of the oldest debates in VMware lore is “How many virtual machines should I place on each datastore?” For this discussion, the context is block storage (as opposed to NFS). There were all sorts of opinions as well as technical constraints to be considered. There was the tried and true rule of thumb answer of 10-15-20 which has more than stood the test of time. The best qualified answer was usually: “Whatever fits best for your consolidated environment” which translates to “it depends” and an invoice in consulting language.
When VAAI was released, I began to notice a slight but alarming trend of credible sources citing claims that the Atomic Test and Set or Hardware Assisted Locking primitive once and for all solved the VMs per LUN conundrum to the point that the number of VMs per LUN no longer mattered because LUN based SCSI reservations were now a thing of the past. To that point, I’ve got marketing collateral saved on my home network that literally states “unlimited number of VMs per LUN with ATS!” Basically, VAAI is the promise land – if you can get there with compatible storage and can afford E+ licensing, you no longer need to worry about VM placement and LUN sprawl to satisfy performance needs and generally reduce latency across the board. I’ll get to why that doesn’t work in a moment but for the time being I think the general public, especially veterans, remained cautious and less optimistic – and this was good.
Then vSphere 5.0 was released. By this time, VAAI was made more highly available and affordable to customers in the Enterprise tier and additional primitives had been added for both block and NFS based storage. In addition, VMware added support for 64TB block datastores without using extents (a true cause for celebration in its own right). This new feature aligned perfectly with the ATS urban myth because where capacity may have been a limiting constraint in the past, that issue has certainly been lifted now. To complement that, consistently growing density drives and reduction of cost/GB in arrays and thin provisioning made larger datastores easily achievable. Marketing decks were updating accordingly. Everything else being equal, we should now have no problem nor hesitation with placing hundreds, if not thousands of virtual machines on a single block datastore as if it were NFS and free from the constraints associated with the SCSI protocol.
The ATS VAAI primitive was developed to address infrastructure latency as a result of LUN based SCSI reservations which were necessary for certain operations such as creating and deleting files on a LUN, growing a file in size, creating and extending datastores. We encounter these types of operations by doing things like powering on virtual machines individually or in large groups such as in a VDI environment, creating vSphere snapshots (very popular integration point for backup technologies), provisioning virtual machines from a template. All of these tasks have one thing in common: they result in the change of metadata on the LUN which in turn necessitates a LUN level lock by the vSphere host making the change. This lock, albeit very brief in duration, drives noticeable storage I/O latency in large iterations for the hosts and virtual machines “locked out” of the LUN. The ATS primitive offloads the locking mechanism to the array which only locks the data being updated instead of locking the entire LUN. Any environment which has been historically encumbered by these types of tasks is going to benefit from the ATS primitive and a reduction of storage latency (both reads and writes, sequential and random) will be the result.
With that overview of ATS out of the way, let’s revisit the statement again and see if it makes sense: “unlimited number of VMs per LUN with ATS!” If the VMs we’re talking about frequently exhibit the behavior patterns discussed above which cause SCSI reservations, then without a doubt, ATS is going to replace the LUN level locking mechanism as the previous bottleneck and reduce storage latency. This in turn will allow more VMs to be placed on the LUN until the next bottleneck is introduced. Unlimited? Not even close to being correct. And what about VMs which don’t fit the SCSI reservation use case? Suppose I use array based snapshots for data protection? Suppose I don’t use or there is a corporate policy against vSphere snapshots (trust me, they’re out there, they exist)? Maybe I don’t have a large scale VDI environment or boot storms are not a concern. This claim I see from time to time makes no mention of use cases and conceivably applies to me as well meaning in an environment not constrained by classic SCSI reservation problem. I too can leverage VAAI ATS to double, triple, place an unlimited amount of VMs per block datastore. I talk with customers on a fairly regular basis who are literally confused about VM to LUN placement because of mixed messages they receive, especially when it comes to VAAI.
Allow me to perfrom some Eric Sloof style VMware myth busting and put the uber VMs per ATS enabled LUN claim to the test. Meet Mike – a DBA who has taken over his organization’s vSphere 5.1 environment. Mike spends the majority of his time keeping up with four different types of database technologies deployed in his datacenter. Unfortunately that doesn’t leave Mike much time to read vSphere Clustering Deepdives or Mastering VMware vSphere but he knows well enough to not use vSphere snapshotting because he has an array based data consistent solution which integrates with each of his databases.
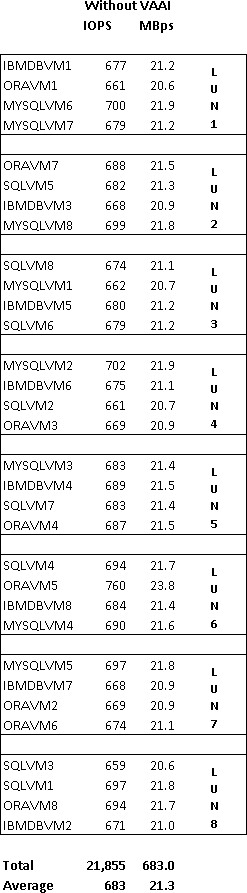
Fortunately, Mike has a stable and well performing environment exhibited to the left which the previous vSphere architect left for him. Demanding database VMs, 32 in all, are distributed across eight block datastores. Performance characteristics for each VM in terms of IOPS and Throughput are displayed (these are real numbers generated by Iometer in my lab). The previous vSphere architect was never able to get his organization to buy off on Enterprise licensing and thus the environment lacked VAAI even though their array supported it.
Unfortunately for Mike, he tends to trust random marketing advice without thorough validation or research on impact to his environment. When Mike took over, he heard from someone that he could simplify infrastructure management by implementing VAAI ATS and consolidate his existing 32 VMs to just a single 64TB datastore on the same array, plus grow his environment by adding basically an unlimited amount of VMs to the datastore providing there is enough capacity.
This information was enough to convince Mike and his management that, risks aside, management and troubleshooting efficiency through a single datastore was definitely the way to go. Mike installed his new licensing, ensured VAAI was enabled on each host of the cluster, and carved up his new 64TB datastore which is backed by the same pool of raw storage and spindles servicing the eight original datastores. Over the weekend, Mike used Storage vMotion to migrate his 32 eager zero thick database VMs from their eight datastores to the new 64TB datastore. He then destroyed his eight original LUNs and for the remainder of that Sunday afternoon, he put his feet up on the desk and basked in the presence of his vSphere Client exhibiting a cluster of hosts and 32 production database VMs running on a single 64TB datastore.
On Monday morning, his stores began to open up on the east coast and in the midwest. At about 8:30AM central time, the helpdesk began receiving calls from various stores that the system seemed slow. Par for the course for a Monday morning but with great pride and ethics, Mike began health checks on the database servers anyway. While he was busy with that, stores on the west coast opened for business and then the calls to the helpdesk increased in frequency and urgency. The system was crawling and in some rare cases the application was timing out producing transaction failure messages.
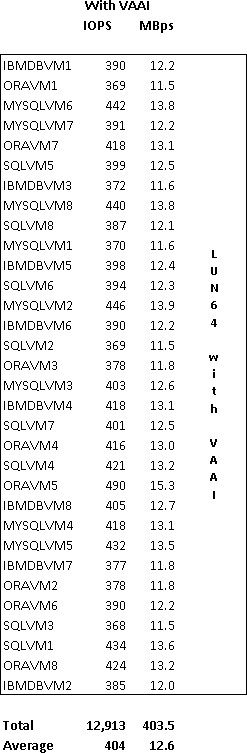
Finding no blocking or daytime re-indexing issues at the database layer, Mike turned to the statistical counters for storage and saw a significant decrease in IOPS and Throughput across the board – nearly 50% (again, real Iometer numbers to the right). Conversely, latency (which is not shown) was through the roof which explained the application timeout failures. Mike was bewildered. He had made an additional investment in hardware assisted offload technology and was hoping for a noticeable increase in performance. Least of all, he didn’t expect a net reduction in performance, especially this pronounced. What happened? How is it possible to change the VM:datastore ratio, backed by the same exact pool of storage Tier and RAID type, and come up with a dramatic shift in performance? Especially when one resides in the kingdom of VAAI?
Queue Depth. There’s only so much active I/O to go around, per LUN, per host, at any given moment in time. When multiple VMs on the same host reside on the same LUN, they must share the queue depth of that LUN. Queue depth is defined in many places along the path of an I/O and at each point, it specifies how many I/Os per LUN per host can be “active” in terms of being handled and processed (decreases latency) as opposed to being queued or buffered (increases latency). Outside of an environment utilizing SIOC, the queue depth that each virtual machine on a given LUN per host must share is 32 as defined by the default vSphere DSNRO value. What this effectively means is that all virtual machines on a host sharing the same datastore must share a pool of 32 active I/Os for that datastore.
Applied to Mike’s two-host cluster, whereas he used to have four VMs per datastore evenly distributed across two hosts, effectively each VM had a sole share of 16 IOPS to work with (1 datastore x queue depth of 32 x 2 hosts / 4 VMs or simplified further 1 datastore x queue depth of 32 x 1 host /2 VMs)
After Mike’s consolidation to a single datastore, 16 VMs per host had to share a single LUN with a default queue depth of 32 which reduced each virtual machine’s active IOPS from 16 to 2.
Although the array had the raw storage spindle count and IOPS capability to provide fault tolerance, performance, and capacity, at the end of the day, queue depth ultimately plays a role in performance per LUN per host per VM. To circle back to the age old “How many virtual machines should I place on each datastore?” question, this is ultimately where the old 10-15-20 rule of thumb came in:
- 10 high I/O VMs per datastore
- 15 average I/O VMs per datastore
- 20 low I/O VMs per datastore
Extrapolated across even the most modest sized cluster, each VM above is going to get a fairly sufficient share of the queue depth to work with. Assuming even VM distribution across clustered hosts (you use DRS in automated mode right?), each host added to the cluster and attached to the shared storage brings with it, by default, an additional 32 IOPS per datastore for VMs to share in. Note that this article is not intended to be an end to end queue depth discussion and safe assumptions are made that the DSNRO value of 32 represents the smallest queue depth in the entire path of the I/O which is generally true with most installations and default HBA card/driver values.
In summary, myth busted. Each of the VAAI primitives was developed to address specific storage and fabric bottlenecks. While the ATS primitive is ideal for drastically reducing SCSI reservation based latency and it can increase the VM: datastore ratio to a degree, it was never designed to imply large sums of or an unlimited number of VMs per datastore because this assumption simply does not factor in other block based storage performance inhibitors such as queue depth, RAID pools, controller/LUN ownership model, fabric balancing, risk, etc. Every time I hear the claim, it sounds as foolish as ever. Don’t be fooled.
Update 3/11/13: A few related links on queue depth:
QLogic Fibre Channel Adapter for VMware ESX User’s Guide
Execution Throttle and Queue Depth with VMware and Qlogic HBAs
Changing the queue depth for QLogic and Emulex HBAs (VMware KB 1267)
Setting the Maximum Outstanding Disk Requests for virtual machines (VMware KB 1268)
Controlling LUN queue depth throttling in VMware ESX/ESXi (VMware KB 1008113)
Disk.SchedNumReqOutstanding the story (covers Disk.SchedQuantum, Disk.SchedQControlSeqReqs, and Disk.SchedQControlVMSwitches)
Disk.SchedNumReqOutstanding and Queue Depth (an article I wrote back in June 2011)
Last but not least, a wonderful whitepaper from VMware I’ve held onto for years: Scalable Storage Performance VMware ESX 3.5
















Great Post Jason……We always said it fixes locking but not Queue Depth!!
All I have to say is bring on vvols! I can’t wait for the end of this kind of minutia dictating our storage designs. I’m a details kind of guy and it still seems like such silly legacy design decisions are dominating modern designs.
Great article. Great site.
Guess why the architect quit myths inc. 😉
I like that you actually verified what we already know that ATS is one thing and queue depth another.
Would it be possible for you to run the benchmark again and record the numbers when you increase the queue depth and see if you could get the same performance on one lun compared to eight?
Great Article…..Shows that Maximums should not always be used when designing VMware/ Storage Environments.
Jason,
Great article with a concise explanation across multiple layers/myths and with realistic conclusion.
Call me crazy, but I still have a “personal limit” of not having more than 10 vm’s perl LUN..Yes I know this may lead to a higher count of LUN’s, but I prefer to manage more LUN’s vs losing performance .
Again..well done!
@Frank Brix Pedersen I can raise the effective queue depth which should provide better results for Mike. In the real world (outside of a lab environment), we’d want to be very cautious about increasing queue depth to the point that it overruns the array, espeically when the array is shared storage for other workloads (they need their fair share too). Let me know what queue depth numbers you’d like me to try (ie. 64, 128, max 256)
@Jason: 64 would be the most realistic I would love to see that. If you wanted to expand on this article you could show screenshots of esxtop and vcenter performance graphs.
It is easy for you to know you have performance issues because you have a baseline to work from. But this is not the case in real life. So basicly add some screenshots that shows how to see your performance is suffering because of the queue depth.
Thanks
This is an awesome writeup with great data! Yay science! Keep up the good fight against poor implementation sir.
I’d like to see the queue depth of 128 and 256 as well. Since in your original test it changed from 16 oustanding IOPS to 2x it’d be great to see how it can be compensated. I manage some environments which have dedicated storage arrays for virtualization, so this is possible.
Also, would like to see all the tests with SIOC enabled as well. I’m not sure the results would be much different because by looking at the numbers it seemed it was enabled (everything seemed evenly split).
Thanks for the information!!
Jason,
I’d be very curious to see the results of a queue depth of 64 as well, as that is the commonly recommended setting stated by some storage vendors in their array best practice guides (perhaps older revisions).
@Jason, This is great stuff. VAAI ATS is not a cure all and other things like DSNRO, schedule quantum time, Type of VM adapter matters.
That said, I have done extensive work in this area on a new medium of storage, All-flash storage arrays at Pure Storage.
I would argue that given the right medium and right settings, we can drive 1000s of VMs and take advantage of the VAAI ATS to be beneficial to guys like Mike. One of the important BP recommendations is to set DSNRO to the max, schedQuantum to max, use Paravirtual adapters.
I have documented them at our blog site, http://www.purestorage.com/blog/virtualization-and-flash-blog-post-3/ and at
http://www.purestorage.com/blog/1000-vms-demo-vmworld-2011/
The new media will change the way we think about virtualizing biz critical appl workloads.
Excellent post!!
I recently did a post myself on VAAI http://blog.enterprisestoragesense.com/2013/01/30/how-flashsoft-handles-vmware%C2%AE-vaai-%E2%80%93-tales-from-the-7th-annual-nevmug-winter-warmer/. We are also frequently asked by customers how many VMs they can place on a single host, so it was with great enthusiasm that I read your post.
May I suggest that by utilizing a relatively small amount of SSD in the host along with server-side caching software such as FlashSoft one can avoid the excessive queuing to a large degree by satisfying I/O from the SSD in the host. With this solution it is now feasible to increase the density of VMs per host. Here are some of our test results indicating what level of increased density may be achieved http://www.sandisk.com/assets/docs/test-report-vm-density.pdf.
Mike’s situation is a classic example of the challenge FlashSoft was designed to address.
Good work Jason, I look forward to more!
We have made a huge difference in overall troughput to the netapp filers with DSNRO and schedQuantum to 64 and device reset to 0. Enabling VAAI has little impact since we just don’t make our datastores too big.
Please correct me if I’m wrong but shouldnt the formula include some factor for the amount of hosts you have?
For example
10 high I/O VMs per datastore per Host
In addition what is the easiest way to measure if you are hitting the Queue depth max? Are there any indicators in vCenter? I understand in this case it was obvious something was wrong and most likely related to the architecture change. Personally I have low iop numbers due to low utilization (I think) however we have pretty high density luns.
Great article and it really helped clear up one of our questions.
It would be great if SDRS could help balance the queue depth as well as the storage and IOPs. Do you know if there is any plan for this to be included?
Did VMWare change the default queue depth for certain adapters starting with ESXi 5.0?
According to this they did just that…
http://kb.vmware.com/selfservice/microsites/search.do?language=en_US&cmd=displayKC&externalId=1267
It seems Qlogic adapters have a default of 64.
Emulex and Brocade adapters have a default queue depth of 32.
I have Qlogic FC storage adapters in my environment. That would mean my default queue depth is 64.
I had a storage architect tell me my LUNs should easily handle more than 20 active VMs and that 2TB LUNs were a good size to go with.