There is a VMware storage whitepaper available which is titled Scalable Storage Performance. It is an oldie but goodie. In fact, next to VMware’s Configuration Maximums document, it is one of my favorites and I’ve referenced it often. I like it because it is efficient in specifically covering block storage LUN queue depth and SCSI reservations. It was written pre-VAAI but I feel the concepts are still quite relevant in the block storage world.
One of the interrelated components of queue depth on the VMware side is the advanced VMkernel parameter Disk.SchedNumReqOutstanding. This setting determines the maximum number of active storage commands (IO) allowed at any given time at the VMkernel. In essence, this is queue depth at the hypervisor layer. Queue depth can be configured at various points in the path of an IO such as the VMkernel which I already mentioned, in addition to the HBA hardware layer, the kernel module (driver) layer, as well as at the guest OS layer.
Getting back to Disk.SchedNumReqOutstanding, I’ve always lived by the definition I felt was most clear in the Scalable Storage Performance whitepaper. Disk.SchedNumReqOutstanding is the maximum number of active commands (IO) per LUN. Clustered hosts don’t collaborate on this value which implies this queue depth is per host. In other words, each host has its own independent queue depth, again, per LUN. How does Disk.SchedNumReqOutstanding impact multiple VMs living on the same LUN (again, same host)? The whitepaper states each VM will evenly share the queue depth (assuming each VM has identical shares from a storage standpoint).
When virtual machines share a LUN, the total number of outstanding commands permitted from all virtual machines to that LUN is governed by the Disk.SchedNumReqOutstanding configuration parameter that can be set using VirtualCenter. If the total number of outstanding commands from all virtual machines exceeds this parameter, the excess commands are queued in the ESX kernel.
I was recently challenged by a statement agreeing to all of the above but with one critical exception: Disk.SchedNumReqOutstanding provides an independent queue depth for each VM on the LUN. In other words, if Disk.SchedNumReqOutstanding is left at its default value of 32, then VM1 has a queue depth of 32, VM2 has a queue depth of 32, and VM3 has its own independent queue depth of 32. Stack those three VMs and we arrive at a sum total of 96 outstanding IOs on the LUN. A few sources were provided to me to support this:
Fibre Channel SAN Configuration Guide:
You can adjust the maximum number of outstanding disk requests with the Disk.SchedNumReqOutstanding parameter in the vSphere Client. When two or more virtual machines are accessing the same LUN, this parameter controls the number of outstanding requests that each virtual machine can issue to the LUN.
VMware KB Article 1268 (Setting the Maximum Outstanding Disk Requests per Virtual Machine):
You can adjust the maximum number of outstanding disk requests with the Disk.SchedNumReqOutstanding parameter. When two or more virtual machines are accessing the same LUN (logical unit number), this parameter controls the number of outstanding requests each virtual machine can issue to the LUN.
The problem with the two statements above is that I feel they are poorly worded, and as a result, misinterpreted. I understand what the statement is trying to say, but it’s implying something quite a bit different depending on how a person reads it. Each statement is correct in that Disk.SchedNumReqOutstanding will gate the amount of active IO possible per LUN and ultimately per VM. However, the wording implies that the value assigned to Disk.SchedNumReqOutstanding applies individually to each VM which is not the case. The reason I’m pointing this out is due to the number of misinterpretations I’ve subsequently discovered via Google which I gather are the result of reading one of the latter sources above.
The scenario can be quickly proven in the lab. Disk.SchedNumReqOutstanding is configured for the default value of 32 active IOs. Using resxtop, I see my three VMs cranking out IO with IOMETER. Each VM is configured with IOMETER to create 32 active IOs. If what I’m being told by the challenge is true, I should be seeing 96 active IO being generated to the LUN from the combined activity of the three VMs.

But that’s not what’s happening. Instead what I see is approximately 32 ACTV (active) IOs on the LUN, with another 67 IOs waiting in queue (by the way, ESXTOP statistic definitions can be found here). In my opinion, the Scalable Storage Performance whitepaper most accurately and best defines the behavior of the Disk.SchedNumReqOutstanding value.
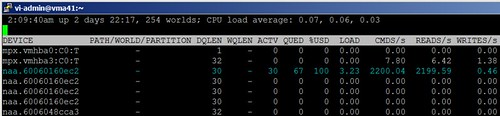
Now going back to the possibility of the Disk.SchedNumReqOutstanding stacking, LUN utilization could get out of hand rapidly with 10, 15, 20, 25 VMs per LUN. We’d quickly exceed the max supported value of Disk.SchedNumReqOutstanding (and all HBAs I’m aware of) which is 256. HBA ports themselves typically support a few thousand IOPS. Stacking the queue depths for each VM could quickly saturate an HBA meaning we’d get a lot less mileage out of those ports as well.
While having a queue depth discussion, it’s also worth noting the %USD value is at 100% and LOAD is approximately 3. The LOAD statistic corroborates the 3:1 ratio of total IO:queue depth and both figures paint the picture of an oversubscribed LUN from an IO standpoint.
In conclusion, I’d like to see VMware modify the wording in their documentation to provide better understanding leaving nothing open to interpretation.
Update 6/23/11: Duncan Epping at Yellow Bricks responded with a great followup Disk.SchedNumReqOutstanding the story.
















Jason – great article, learnt something new.
What do you think of setting queue depths based on the number of LUN’s in your cluster?
The Scalable Storage Performance PDF has a great bit on page 5 about it.
Andy
Modifying queue depth on the HBAs and at the Disk.SchedNumReqOutstanding layer can squeeze extra mileage out of the array in some cases (think small implementations with either no growth or slow and predictable growth to stay ahead of any future queue depth changes needed). But as with any knob turning situation, one has the ability to accidentally introduce storage latency. SCSI has been around a long time giving it a lot of time to mature. I think many consultants would agree that the default queue depth values are best for the largest variety of scenarios & storage types. In addition, the default values will scale the best with less burden on the capacity planning side down the road as a result of tweaks to queue depth. However, recommendations may vary depending on storage subsystem. Consult with your vendor. I’ve heard of one storage vendor which recommends a significantly deep queue depth due to the unique way this vendor writes to disk. For what it’s worth, I modified the queue depth in my VCDX defense for a smaller sized datacenter with an HP brand SMB fibre channel array (and successfully defended).
Nice article Jason!,
Jason – would you agree that the KISS principle applies if no vendor recommendation can be determined?
I was reviewing the Hitachi VSP “Best Practice Guide” and they have a very interesting formula for determining the “best” queue depth based on the number of disks, LUNs and HBA’s in the cluster.
http://www.hds.com/assets/pdf/optimizing-the-hitachi-virtual-storage-platform-best-practices-guide.pdf
see page 35.
KISS applies when the design decision involves ROI, administrative burden, performance, risk, etc. VMware and their partners have come up with standards, defaults, and best practices based on more testing than you will ever likely attempt. If you think you’ve got a corner case, you’ll need to go through the due diligence of at least initial exploration. Assuming you’ve got support, don’t be afraid to lean on vendors for assistance (HDS, VMware, integrator, etc.)
I provided some more details around this setting here: http://www.yellow-bricks.com/2011/06/23/disk-schednumreqoutstanding-the-story/
Great article Jason.
I was very interesting to read
Hi Jason,
great article, but I would like to add an extra question.
When adjusting the HBA queue depth, what would be the math behind it?
I. e. the emulex HBA driver I did use report a value of 2038 in AQLEN (as per esxtop output for disk adapters)
When the HBA is zoned to two ports (targets) of an A/P array with 50 LUN’s provisioned for the ESX Server, what would be the maximum HBA queue depth value?
In my understanding, the math should look like this:
Q = AQLN/(# Target * # LUN’s)
For my example this would mean:
Q = 2038/(2*50) = 2038/100 = 20
IMHO, this should be correct even when we take in mind that ESX does only uses one path to a LUN (except when using PP/VE).
Simply because the HBA need to share his queues evenly to all seen devices, regardless if that path is used or not.
But maybe we could use some kind of conservative oversubscription???
And sure we also need to keep in mind that within a VMware environment LUN’s are usually shared between multiple servers.
So adjusting the HBA queue depth on all servers might cause a QFull condition on the used array.
Would really appreciate a feedback on this.
Regards
Ralf